BERT: Bidirectional Encoder Representations from Transformers
BERT 모델은 Transformer 모델을 기반으로 한다. Transformer 아키텍처의 encoder 부분만을 사용한다. Encoder 부분에서 self attention mechanism을 적용하는데 여기서 token간의 관계를 파악하기 위해 입력 sequence의 모든 token을 사용한다. 따라서 BERT를 bidirectional 모델이라고 한다. 이와 달리 GPT는 Transformer의 decoder 부분만을 사용한다. GPT는 다음에 이어질 token을 예측할 때 앞의 token만을 참조하도록 뒤의 token을 masking한다. GPT는 bidirectional 모델이 아니다.
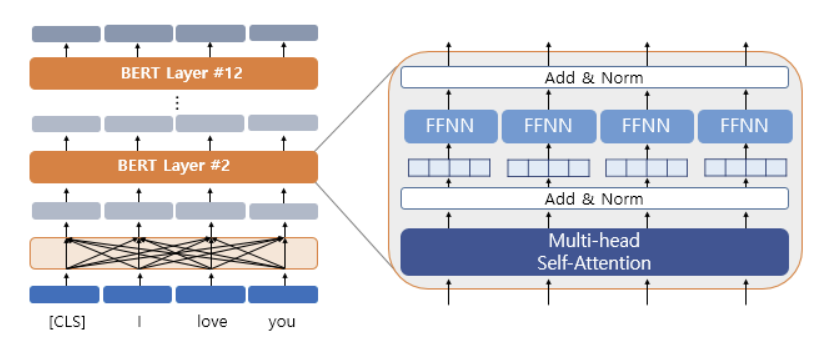
BERT는 두 단계의 학습 과정을 거친다.
- Pretraining: Wikipedia와 같은 대량의 텍스트 데이터를 사용하여 일반적인 언어 지식을 학습한다.
- Fine-tuning: Pretraining에서 학습된 모델을 특정 작업에 맞게 미세 조정한다. 예를 들어 상품 리뷰가 긍정적인지 부정적인지를 분류하는 감정 분석을 한다면 fine-tuning 과정에서 긍정 또는 부정 label이 있는 리뷰 데이터셋을 사용하여 모델을 추가로 학습시킨다.
BERT의 가장 큰 장점 중 하나는 transfer learning을 통해 다양한 NLP 작업에 쉽게 적용될 수 있다는 것입니다. 일반적인 언어 이해 능력을 pretraining을 통해 학습한 뒤, 특정 작업에 맞게 fine-tuning하면 빠르게 높은 성능을 얻을 수 있습니다.
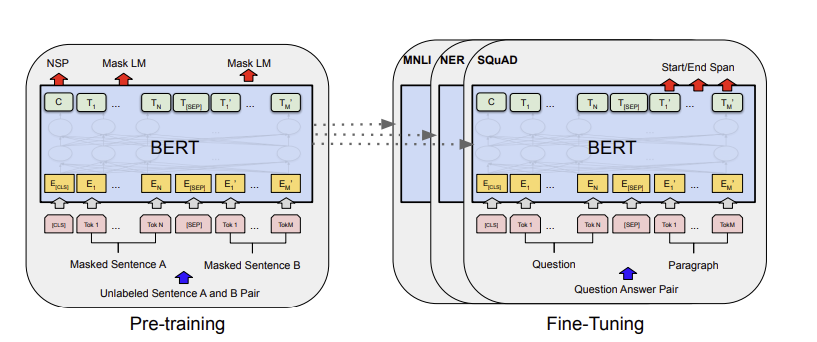
Fine-Tuning 부분에 MNLI, NER, SQuAD 층이 추가되어 있다. 특정 작업을 위한 층을 추가한 것이다.
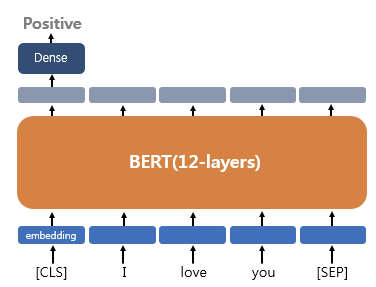
예를 들어 상품 리뷰 감정 분석과 같은 text analysis라면 [CLS] token 위치의 출력층에서 dense layer(= fully-connected layer) 층을 추가하여 예측을 수행한다.
BERT는 pretraining 과정에서 MLM(Masked Language Model) 작업을 하면서 문맥을 파악하는 능력을 길러낸다. 특정 token을 무작위로 선택하고 그 token을 [MASK]로 표시한다. 그리고 모델은 [MASK] token의 원래 값을 예측하려고 한다. 그 후보는 주로 모델의 어휘 사전 내에서 선택된다. 모델이 [MASK]를 예측하고 실제 정답 token과 비교하여 loss를 계산하고 모델을 업데이트한다. BERT 모델은 전체의 15%를 [MASK]라는 special token으로 바꾼다. 그리고 이 15%의 단어들에 대해서 원래 값을 예측한다. 나머지 85%에 대해서는 예측하지 않는다. 그런데 이 [MASK] token은 pretraining 단계에서만 사용되고 감정 분석과 같은 실제 작업에서는 대부분 입력 데이터로 [MASK]가 들어오지 않는다. 이런 상황에서 실제 작업 입력 데이터로 [MASK] token이 들어왔을 때 모델은 [MASK] token을 처리하는 데 과도하게 최적화될 수 있다. 이를 방지하기 위해서 모델은 pretraining 과정에서 [MASK] token을 다음과 같이 처리한다.
- 80%를 [MASK]로 둔다.
- 10%를 랜덤한 단어로 변경한다.
- 10%를 동일한 단어로 둔다.
BERT 입장에서는 어떤 단어가 어떤 방식으로 변경되었는지 모른다. 모델은 단순히 주어진 입력을 보고 원래 단어가 무엇이었는지 예측하려고 한다.
대부분의 모델은 한 방향에서만 학습한다. 하지만 BERT는 MLM 작업을 통해 주어진 문장 내의 모든 단어들로부터 정보를 수집하여 특정 단어를 예측한다. 이렇게 하면 모델은 문장의 전체 맥락을 이해하려고 노력하게 되고 결과적으로 더 효과적으로 문장의 정보를 학습할 수 있다.
BERT는 pretraining 과정에서 NSP(Next Sentence Prediction) 작업을 수행한다. 두 개의 문장이 주어지면 두 문장이 연결되어 있는 문장인지 예측한다. 50%는 연결된 문장이고 50%는 랜덤하게 뽑힌 문장이다. 두 문장이 이어지는 문장인지 판별할 때 [CLS] token 위치의 출력층에서 binary classification 문제를 풀도록 한다. NSP 작업을 통해서 문장 간의 relationship을 파악할 수 있다.
BERT에는 총 3개의 임베딩 층이 사용된다.
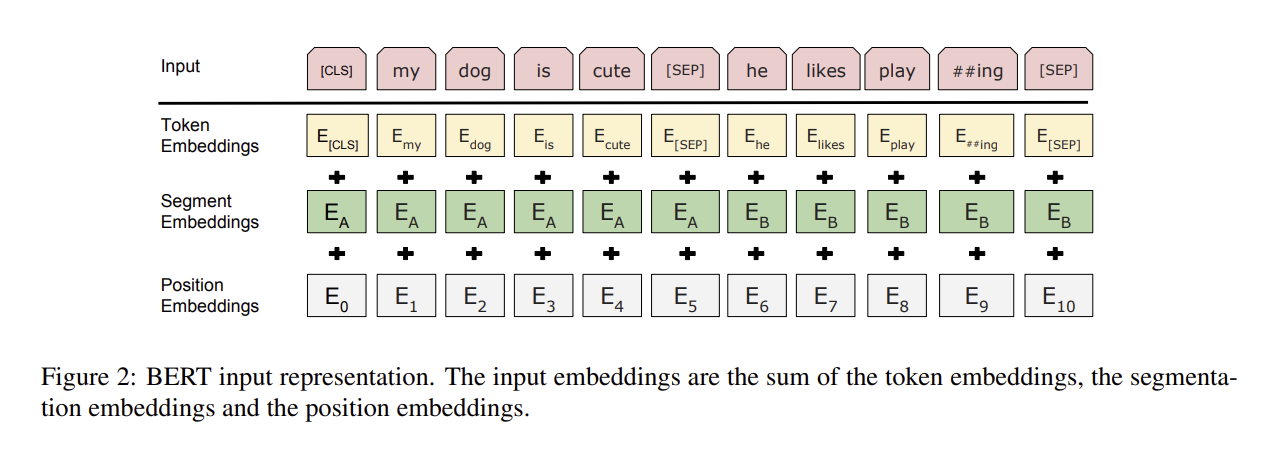
Position embedding에서는 위치 정보를 학습하게 된다. Segment embedding은 두 개의 문장을 구분하기 위한 임베딩이다.
BERT 모델의 학습 과정
- 입력 처리: 한 개 또는 두 개의 문장이 입력으로 들어온다. 이 때 일부 단어들은 [MASK]로 masking 된다. 또한 [CLS]와 [SEP] token들이 추가된다.
- Transformer Encoder 처리: 입력 문장이 multi-head attention과 feed forward network로 구성된 encoder 층을 통과한다.
- MLM: Encoder의 최종 출력에서 [MASK] token 위치의 출력층에서 원래 단어를 예측한다. 이 예측은 softmax 층을 통해 수행되며 원래 단어와 예측 단어 간의 차이를 최소화하는 방향으로 학습된다.
- NSP: [CLS] token 위치의 출력층에서 두 문장이 연속적인 관계에 있는지 예측한다. 이 또한 softmax 층을 통해 이루어진다.