RoBERTa: A Robustly Optimized BERT Pretraining Approach
BERT was significantly undertrained. 따라서 BERT 모델의 변형 모델인 RoBERTa를 제시한다.
더 많은 양의 데이터를 사용하여 훈련
BERT의 학습 데이터는 BOOKCORPUS와 English WIKIPEDIA였다. RoBERTa는 이 두 데이터셋 이외에도 다양한 웹 페이지에서 수집한 데이터를 훈련에 포함시켰다. 뉴스 기사가 수집된 CC-NEWS, 인터넷의 다양한 웹 페이지와 기사를 크롤링하여 만든 OPENWEBTEXT, story 스타일의 STORIES가 있다.
Training with Large Batches
하나의 batch에 포함되는 sample의 수를 늘려서 optimization speed를 높이고 성능을 향상시킨다.
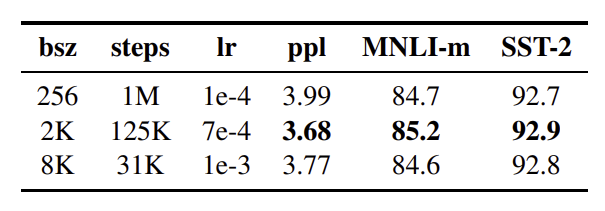
Batch size를 늘려서 large batch로 훈련시켰을 때 perplexity가 낮아지고 성능이 좋아진다.
Dynamic Masking
BERT는 일정 비율의 token을 masking한다. 이때 각 epoch에서 동일한 위치의 token이 masking된다. 이것을 static masking이라고 한다. 하지만 RoBERTa에서는 학습 데이터가 10배가 되도록 복제하여 40번의 epoch 동안 동일한 문장에 대해 10개의 다양한 masking 패턴을 볼 수 있도록 한다. 즉 학습 도중 같은 masking 패턴을 4번씩 보게 된다.
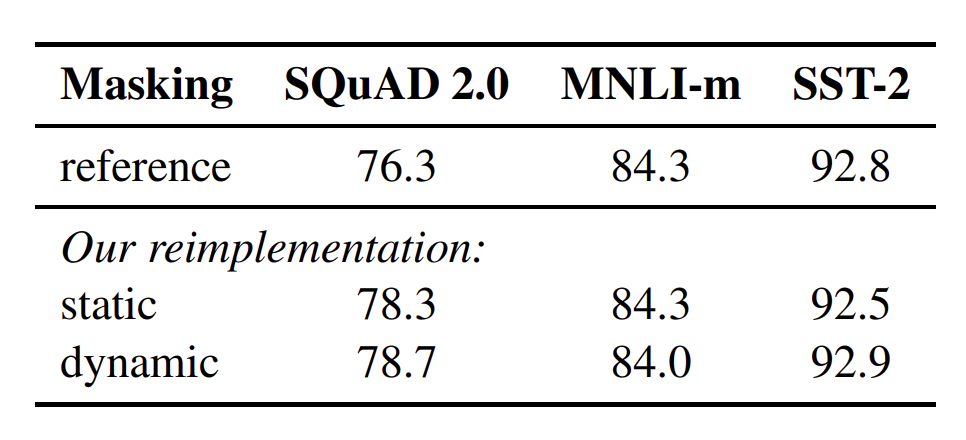
NSP(Next Sentence Prediction) 제거
BERT에서는 학습할 때 두 개의 document segment를 합쳐서 input으로 사용한다. 이때 50%를 같은 document에서 가져오고 50%를 다른 document에서 가져온다. 그리고 두 segment가 같은 document에서 온 것인지 예측한다. RoBERTa는 이 NSP 작업을 제거하였고 NSP 없이도 성능이 향상됨을 발견했다.
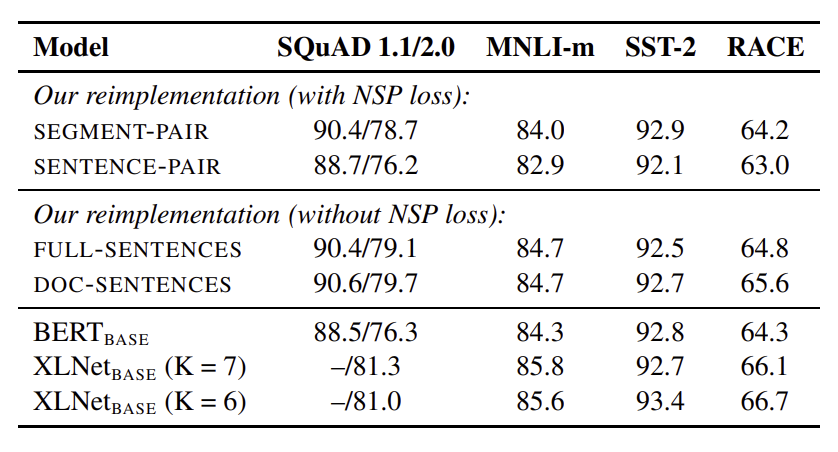
Segment-Pair에서는 각 input에 여러 개의 문장이 들어올 수 있다. Sentence-Pair에서는 각 input에 하나의 문장이 들어오게 된다. 이 두 경우에서는 NSP를 제거하지 않는다. Segment-Pair와 Sentence-Pair을 비교하면 Segment-Pair가 더 성능이 좋다. Sentence-Pair에서는 모델이 멀리 떨어져 있는 정보 사이 관계를 제대로 파악할 수 없기 때문이라고 추측한다. Full-Sentences에서는 각 input에 여러 개의 문장이 들어오는데 하나의 document가 끝이 나면 다음 document에서 문장을 가져온다. 하지만 Doc-Sentences에서는 document의 boundary를 넘지 않는다. 그래서 input이 최대 길이인 512보다 짧을 수 있기 때문에 batch size를 동적으로 늘린다. 이 두 경우에서는 NSP를 제거한다. Doc-Sentences와 BERT_base를 비교해보면 NSP를 제거한 Doc-Sentences가 더 성능이 좋다. 마지막으로 Doc-Sentences와 Full-Sentences를 비교해보면 Doc-Sentences가 성능이 더 좋다. 그러나 Doc-Sentences는 batch size를 조정해야 하기 때문에 Full-Sentences를 채택하였다.
Text Encoding 방법 변경
BERT는 WordPiece라는 subword tokenizer를 사용한다. WordPiece tokenizer에서는 자주 사용되는 문자열은 그대로 token으로 만들고, 그렇지 않은 문자열은 더 작은 부분(subword)으로 나누어서 token을 만든다. 이렇게 하면 어휘 사전에 없는 단어에 대해서 효과적으로 encoding할 수 있다. 여기서 BERT는 unicode 문자를 기본 단위로 token을 만든다. 하지만 RoBERTa는 subword를 나누는 방식이 BERT와 다르다. RoBERTa는 byte를 기본 단위로 token을 만들도록 하였다. 즉 RoBERTa는 BPE(Byte Pair Encoding) 방식을 사용하였다. BPE는 WordPiece보다 성능이 약간 떨어진다. 그럼에도 불구하고 BPE는 WordPiece와 달리 전처리 과정이 필요가 없고 더 다양한 언어와 도메인에 대해 encoding이 가능하기 때문에 BPE를 채택하였다.
즉 RoBERTa는 dynamic masking을 사용했고 , NSP를 제거한 Full-Sentences를 채택했고, batch size를 늘렸으며, BPE 방법으로 encoding을 하였다. 그리고 모델을 training할 때 BERT_large 모델과 동일한 architecture를 사용하였다. 그리고 training할 때 더 많은 데이터를 사용하는 것과, 훈련 횟수를 늘리는 것도 고려하였다.
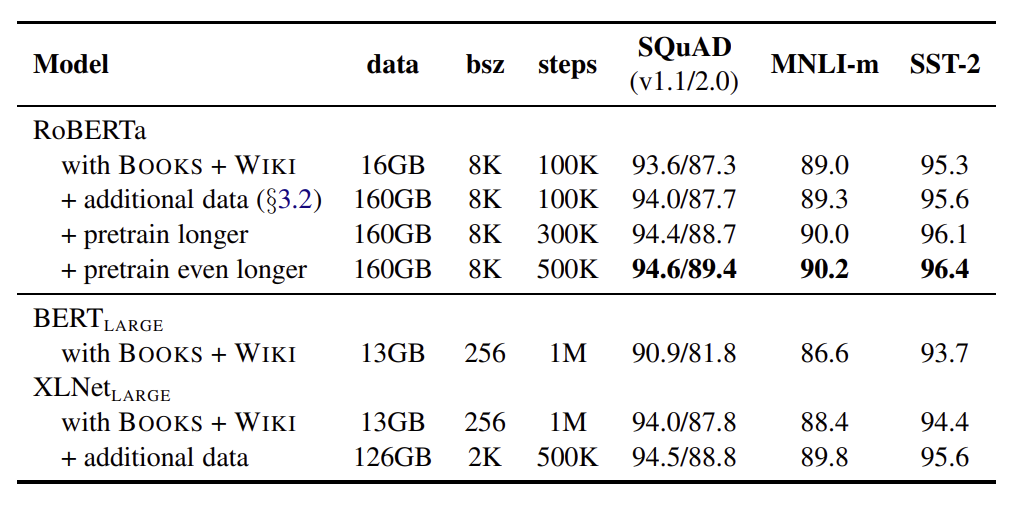
BERT_large나 XLNet_Large 모델과 비교하면 RoBERTa 모델은 성능이 크게 향상되었다. 그리고 더 많은 데이터로 학습을 했을 때 성능이 더 향상되었고, 학습 횟수를 늘렸을 때에도 성능이 향상되었다.
Paper