DeBERTa: Decoding-Enhanced BERT with Disentangled Attention
DeBERTa improves the BERT and RoBERTa models using two novel techniques.
- Disentangled attention mechanism: DeBERTa는 전통적인 attention mechanism과 달리 content-based attention과 position-based attention으로 분리함
- Enhanced mask decoder: [MASK] token을 예측할 때 absolute position을 고려함
이 technique를 사용하였더니 RoBERTa_large 모델이 학습에 사용한 데이터를 반만 사용했는데도 더 높은 성능을 달성하였다.
Disentangled Attention Mechanism
기존의 BERT 모델의 input 층에서 각 단어는 word embedding과 position embedding의 합으로 표현이 된다. 하지만 DeBERTa에서 각 단어는 content를 encoding한 벡터, position을 encoding한 벡터 두 가지로 표현이 된다.
즉 position $i$ 위치의 token을 두 가지 벡터, content를 나타내는 ${H_i}$와 position $j$ 위치의 token과의 relative position을 나타내는 ${P_{i \vert j}}$로 표현한다.
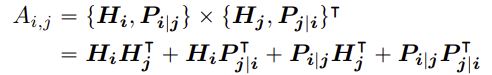
이렇게 cross attention score는 네 가지 요소로 분해된다.
- $H_i H_j^T$: content-to-content
전통적인 attention mechanism에서 사용되는 방식으로 하나의 token의 내용 정보와 다른 token의 내용 정보 간의 관계를 나타낸다.
- $H_i P_{j \vert i}^T$: content-to-position
단어의 내용 정보와 특정 위치 정보 간의 관계를 나타내며 단어의 하나의 token이 문장의 어떤 위치에 있을 확률이 높은지 판단할 때 쓰인다.
- $P_{i \vert j} H_j^T$: position-to-content
특정 위치 정보와 다른 단어의 내용 정보 간의 관계를 나타내며 문장의 특정 위치에서 가장 관련성이 높은 token이 무엇인지 판단할 때 쓰인다.
- $P_{i \vert j} P_{j \vert i}^T$: position-to-position
두 token의 상대적 위치 간의 관계를 나타낸다. 그런데 이 정보는 고정적이며 변하지 않는다. 모든 input sequence에 대해 동일한 정보를 제공하므로 가치가 없다. 따라서 삭제한다.
DeBERTa의 self-attention 계산은 다음과 같다.
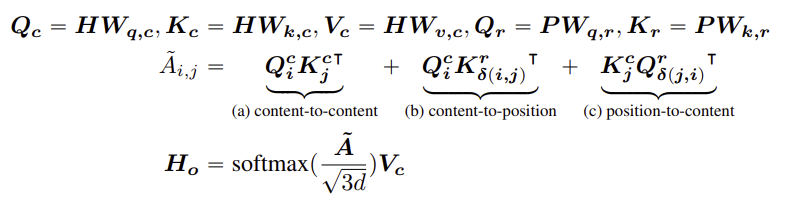
$Q_c$, $Q_c$, $V_c$는 content 벡터이고 $Q_r$, $K_r$는 relative position 벡터이다.
Enhanced Mask Decoder (EMD)
BERT 모델과 마찬가지로 DeBERTa는 pretraining을 할 때 MLM 작업을 수행한다. Disentangled attention mechanism에서는 content와 relative position을 고려한다. 그런데 여기서 absolute position은 고려되지 않는데 [MASK] token을 예측할 때 absolute position은 상당히 중요한 역할을 한다.
A new store opened beside the new mall.
이 문장에서 store과 mall이 모두 [MASK] token으로 대체되었다고 가정해보자. 두 단어 모두 new라는 단어 바로 뒤에 위치하기 때문에 relative position만 고려하면 둘 사이의 구별이 명확하지 않다. 그리고 store는 문장의 주어이기 때문에 문장의 시작 부분에 위치한다. 그래서 opened라는 동사와 직접적인 관계가 있는 반면, mall은 beside라는 전치사와 관련이 있다. 이러한 문법적인 특성을 고려하기 위해서는 absolute position을 고려하는 것이 필수적이다.
BERT 모델에서는 input 층에서 각 단어를 word embedding과 position embedding의 합으로 표현하기 때문에 input 층에서 aboslute position을 고려한다. 그러나 DeBERTa 모델에서는 Transformer 층 다음에, 그리고 [MASK] token을 예측하는 softmax 층 직전에 absolute position을 고려하게 한다.
Scale Invariant Fine-Tuning (SiFT)
모델을 fine-tuning하는 동안 효과적으로 학습하기 위해 새로운 adversarial training method를 제안한다. 여기서 adversarial training method는 모델의 예측을 헷갈리게 하기 위해 input 데이터에 작은 변화를 추가하는 방식으로 모델의 robustness를 향상시키는 효과가 있다. 즉 정상 데이터와 adversarial sample을 같이 학습하여 일반화 성능을 향상시키는 것이다. 원래는 이 noise가 word embedding에 주어진다. 그런데 모델이 크면 embedding 벡터의 크기가 달라지면서 분산이 커지고 학습이 불안정해질 수 있다. 그래서 이 noise를 embedding 벡터를 정규화한 후 적용하는 방법을 제시한다.
Result
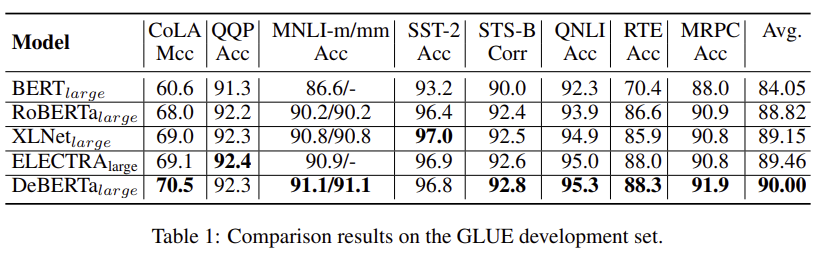
DeBERTa는 BERT와 RoBERTa와 비교했을 때 모든 작업에서 성능이 향상되었다. XLNet과 비교했을 때에는 8개 중 6개의 작업에서 높은 성능을 보인다.
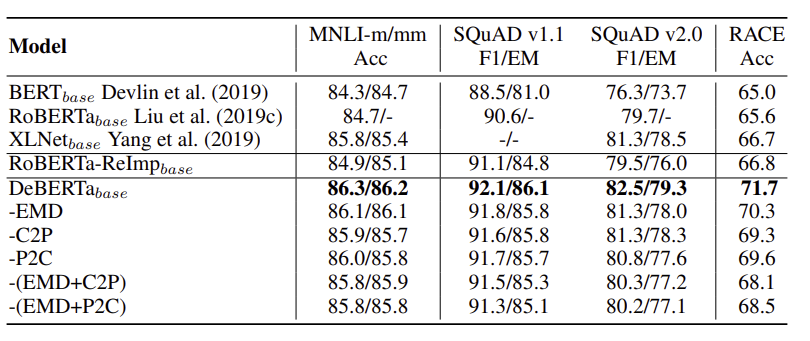
모델의 특정 부분을 제거한 후 성능을 측정한 표이다. EMD, C2P, P2C 모두 포함했을 때 성능이 가장 좋다. 따라서 어느 하나라도 제거해서는 안된다는 것을 확인할 수 있다.
Paper