DistilBERT, a distilled version of BERT: smaller, faster and lighter
DistilBERT는 BERT라는 대형 언어 모델을 가볍게 만든 모델이다. BERT 모델에 비해 모델 size를 40%로 줄였지만 BERT 모델 성능의 97%를 달성했고 60% 빨라졌다.
DistilBERT 모델이 나오게 된 배경: 큰 규모의 언어 모델의 문제점
- environmental cost: 대규모 언어 모델의 연산 요구 사항이 기하급수적으로 증가하면서 이러한 모델들을 훈련시키는 데 필요한 전력 소비가 크게 증가함
- 넓은 적용의 제약: 큰 규모의 언어 모델들이 상당한 양의 연산 능력과 메모리를 필요로 하면서 제한된 resource를 가진 환경에서의 적용이 어려움 (스마트폰과 같은 edge 디바이스에서 실행하기 어려움)
Knowledge Distillation
모델의 크기를 줄이는 기법으로 큰 모델(teacher 모델)의 지식을 작은 모델(student 모델)로 전달하는 학습 방법이다. 즉 knowledge distillation은 teacher 모델의 일반화 능력과 학습한 지식을 student 모델에게 전달한다.
예를 들어 이미지 분류 문제에서 고양이 이미지가 있으면 고양이에 대한 확률이 높아 고양이로 분류될 것이다. 그리고 나머지 label에 대한 확률은 낮을 것이다. 그런데 고양이와 강아지는 발이 네 개라는 것과 같이 유사성이 높다. 그래서 강아지에 대한 확률은 다른 label에 비해 상대적으로 높을 수 있다. 그리고 고양이와 트럭은 유사성이 매우 낮다. 따라서 트럭에 대한 확률은 강아지에 대한 확률보다 훨씬 작을 것이다. 이것을 dark knowledge라고 한다. 이것은 teacher 모델의 softmax 출력에 숨겨진 명시적이지 않은 지식을 나타내며 student 모델에 전달할 가치가 있다.
Student 모델은 이러한 dark knowledge을 배우길 원한다. 하지만 성능이 높은 모델은 정답 label에 대해서 1에 가까운 높은 확률을 반환하고 다른 label에 대해서는 0에 매우 가까운 확률을 반환한다. 이런 경우에는 dark knowledge를 추출하기 쉽지 않다. 따라서 softmax의 출력을 조절하기 위해 softmax 함수의 식에 temperature라는 것을 추가한다. 이 temperature 값이 1보다 클 경우 확률 분포는 더 부드러워지고 각 label 대한 확률이 서로 가까워진다.
\[p_i = \frac{\exp(z_i / T)}{\Sigma_j \exp(z_j / T)}\]여기서 $z_i$는 class $i$에 대한 확률이다. 이 부드러운 확률 분포를 student 모델이 학습하도록 하면 teacher의 결정 경계 주변의 불확실성을 더 잘 포착하여 모델의 일반화 능력을 향상시킬 수 있다.
DistilBERT 모델은 세 가지 loss를 사용한다.
Distillation loss는 다음과 같다. $t_i$는 teacher 모델의 확률, $s_i$는 student 모델의 확률이다.
\[L_{ce} = \sum_i t_i \times \log(s_i)\]Supervised training loss는 다음과 같다. 여기서 $\log P(y_i \vert x_i, \theta)$는 주어진 입력 $x_i$와 모델 parameter $\theta$에 대해 $i$번째 위치에 $y_i$가 나타날 확률을 나타낸다. $y_i$는 실제 $i$번째 위치의 label이다. 그리고 $x_i$는 $i$번째 token을 제외한 모든 token의 sequence이다.
\[L_{mlm} = - \sum_{i \in M} \log P(y_i | x_i, \theta)\]Cosine embedding loss는 다음과 같다. 이 loss는 두 벡터가 얼마나 유사한 방향을 가지고 있는지 측정한다. 두 벡터가 유사할수록 cosine 거리는 0에 가까워지고 두 벡터가 다를수록 cosine 거리는 1에 가까워진다. DistilBERT 모델은 student 모델의 hiddent state 벡터와 teacher 모델의 hidden state 벡터가 방향적으로 유사하도록 훈련시킨다. 여기서 벡터의 방향이 유사하다는 것은 동일한 특성이나 패턴에 대해 유사한 표현을 가지고 있다는 것을 의미한다.
\[L_{cos} = 1 - \frac{v_{teacher} \cdot v_{student}}{||v_{teacher}||_2 ||v_{student}||_2}\]DistilBERT의 final training loss는 이 세 벡터의 linear combination이다.
\[L_{total} = \alpha L_{ce} + \beta L_{mlm} + \gamma L_{cos}\]
Student DistilBERT 모델
- NSP 제거함: token-type embedding과 pooler을 제거하였다. 여기서 token-type embedding은 segment embedding과 같은 말로 NSP 작업에서 각 토큰이 첫 번째 문장에 속하는지 혹은 두 번째 문장에 속하는지 나타낸다. 그리고 pooler는 [CLS] 토큰의 표현을 처리한다. [CLS] 토큰은 문장 전체 의미를 포착하도록 설계되었다. Pooler는 이 토큰 출력을 취하여 밀집된 벡터로 변환한다. 그리고 이 벡터는 downstream 작업에 사용된다.
- layer 수를 절반으로 줄임: 상대적으로 hidden state 벡터의 dimension을 줄이는 것보다 layer 수를 줄이는 것이 computation efficiency가 크다.
- Initialization: Teacher 모델과 student 모델은 각 layer에서 동일한 차원의 hidden state를 가진다. Teacher 모델은 student 모델보다 layer 수가 2배 많다. 따라서 teacher 모델의 2개의 layer마다 1개의 layer의 parameter를 student 모델로 가져와서 initialization한다.
Result
Table 1

DistilBERT 모델은 BERT 모델의 97% 정도 성능을 유지한다.
Table 2
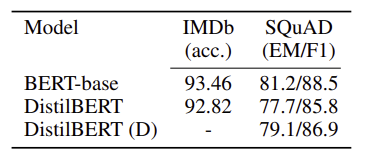
DistilBERT는 downstream 작업에서 BERT와 비슷한 성능을 보인다. IMDb는 감정 분석을 위한 데이터셋이고 SQuAD는 question-answering을 위한 데이터셋이다.
Table 3
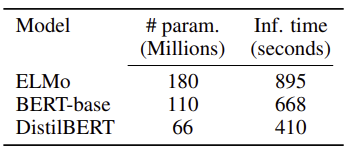
DistilBERT 모델은 BERT 모델에 비해 parameter 수가 줄어들었고 더 빠르다.
Table 4 (Ablation study)

영향력: $L_{mlm}$ < $L_{cos}$ < $L_{ce}$
Initialization을 random하게 했을 때 성능이 제일 하락했다.
Paper