ALBERT: A Lite BERT for Self-Supervised Learning of Languange Representations
ALBERT 모델은 BERT 모델의 효율성과 크기 문제를 해결하기 위해 개발된 변형 모델이다. 기본적인 architecture는 BERT와 유사하지만 몇 가지 핵심적인 차이점을 가지고 있어 큰 모델을 효율적으로 학습하며 좋은 성능을 보인다.
모델의 크기가 커지면서 생기는 문제점
- GPU/TPU memory limitations
- Longer training times: 큰 모델을 사용하면서 분산 학습을 하기도 한다. 그런데 큰 모델에서 분산 학습을 하면 더 많은 데이터를 교환하고 동기화해야 하기 때문에 통신에 드는 비용이 증가한다. 이것을 communication overhead라고 하며 분산 학습 환경에서 여러 머신이나 processor 간에 데이터를 교환할 때 발생하는 추가적인 시간이나 resource를 말한다.
이를 해결하기 위해 model parallelization이나 clever memory management 방법이 있었지만 이 방법들은 memory limitation 문제는 해결하였으나 communication overhead 문제는 해결할 수 없었다.
ALBERT 모델이 제안하는 parameter reduction technique
- Factorized embedding parameterization: 보통 vocabulary embedding matrix는 어휘 크기 x embedding dimension의 크기를 가진다. 이 큰 vocabulary embedding matrix를 두 개의 작은 matrix로 분해한다.
- Cross-layer parameter sharing: 각 layer마다 parameter를 공유하여 layer가 많아지더라도 parameter 수가 늘지 않도록 한다.
이렇게 해서 ALBERT 모델은 BERT_large 모델보다 parameter가 18배 적고 training speed가 1.7배 빠르다. 그리고 이 parameter reduction technique는 regularization 효과도 있다. 모델 parameter 수가 줄어들면 모델이 training data에 과적합하는 것을 방지할 수 있기 때문이다.
Factorized Embedding Parameterization
큰 vocabulary embedding matrix를 두 개의 작은 matrix로 분해하는 방법이다. 기본 아이디어는 input token embedding과 hidden layer embedding으로 나누는 것이다. 여기서 input token embedding은 context-independent하게 token을 표현하고 hidden layer embedding은 context-dependent하게 token을 표현한다. Input token embedding이 여러 layer를 통과하면서 각 layer에서 문맥 정보를 흡수하기 때문이다. 예를 들어 ‘bank’라는 단어가 input token embedding에서는 ‘강둑’의 의미인지 ‘은행’의 의미인지 구분할 수 없다. 하지만 각 layer를 거치면서 문맥을 고려하면서 ‘bank’라는 단어가 둘 중 어떤 의미로 사용되었는지 그 문맥 정보를 포함하게 된다. BERT 모델에서는 input token embedding size(E)와 hidden size(H)가 같다. 즉 input token을 embedding할 때의 벡터 크기와 모델 내부 layer에서의 벡터 크기가 동일하다. 하지만 ALBERT 모델에서는 이 두 개념을 분리한다. ALBERT 모델에서는 input token embedding size를 작게 설정한 다음에 이것을 모델 내에서 큰 차원의 hidden size로 확장하는 추가적인 layer를 사용한다. 즉 ALBERT 모델에서는 input token을 더 작은 벡터로 표현한 다음에 이를 내부적으로 더 큰 차원의 벡터로 projection하여 parameter 수를 줄인다. 이렇게 하면 vocabulary embedding의 parameter 크기는 작은 차원에만 의존하게 되고 hidden size를 늘리더라도 vocabulary embedding의 parameter 크기는 크게 늘어나지 않는다. BERT 모델에서 parameter의 크기가 O(V X H)이었다면 ALBERT 모델에서는 O(V X E + E X H)로 줄어든다. BERT 모델에서는 V의 크기를 늘렸을 때 parameter 개수가 엄청나게 증가하는 반면 ALBERT 모델에서는 V의 크기를 늘리더라도 parameter 개수가 과도하게 증가하지 않는다.
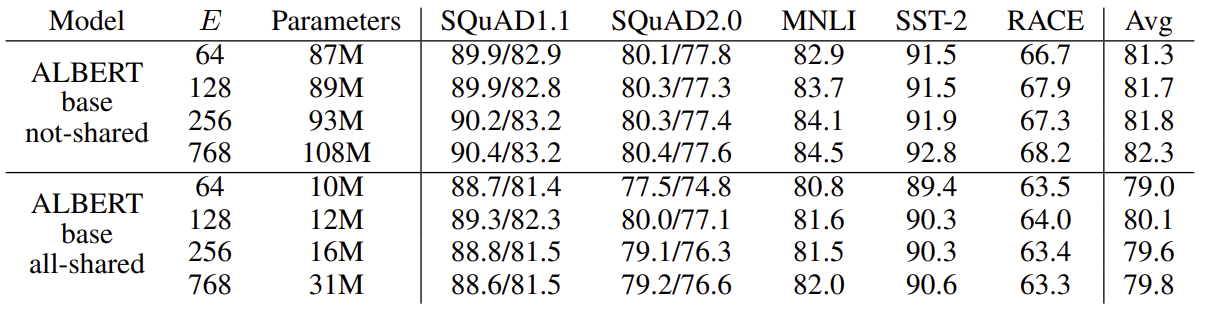
여기서 E는 vocabulary embedding size이다. Cross-layer parameter sharing 기법을 사용하지 않은 경우에 E의 크기가 커질수록 성능이 좋아진다. 하지만 좋아지는 정도는 크기 않다. 하지만 각 layer마다 parameter를 공유했을 때에는 E가 128일 때 성능이 가장 좋다. 이에 따라 위 논문에서는 E를 128로 설정하였다.
Cross-Layer Parameter Sharing
각 layer마다 parameter를 공유한다. 그 방법에는 각 layer마다 모든 parameter를 공유하는 것, feed-forward network에서만 parameter를 공유하는 것, attention parameter만 공유하는 것이 있다. ALBERT 모델은 default로 각 layer마다 모든 parameter를 공유한다. 이렇게 각 layer마다 parameter를 공유하면 parameter가 안정화되는 효과가 있다.
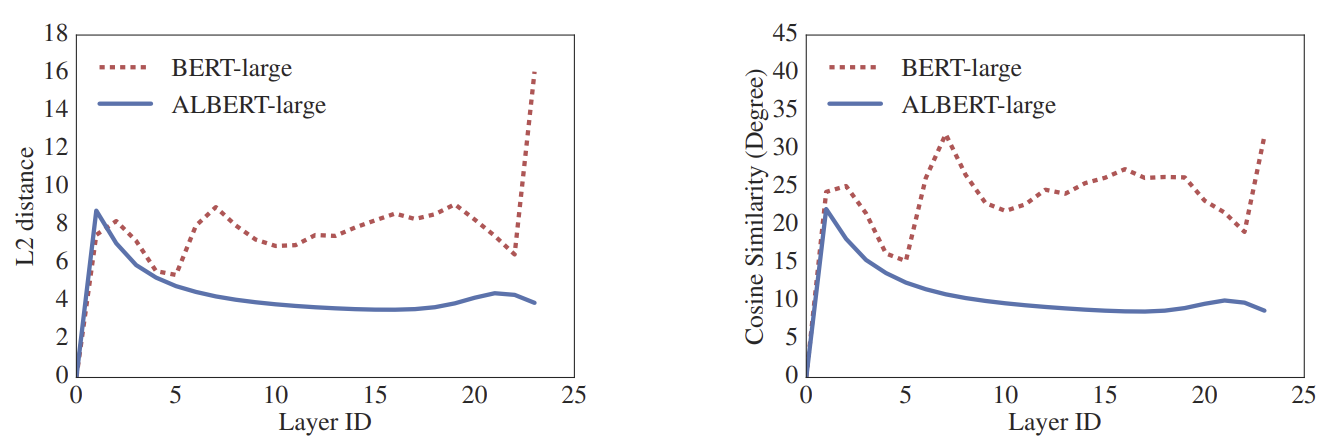
위 그래프는 input embedding과 output embedding의 유사도를 L2 distance와 cosine similarity로 측정한 결과이다. BERT_large 모델과 달리 ALBERT 모델은 layer를 거치면서 유사도가 부드럽게 변한다.
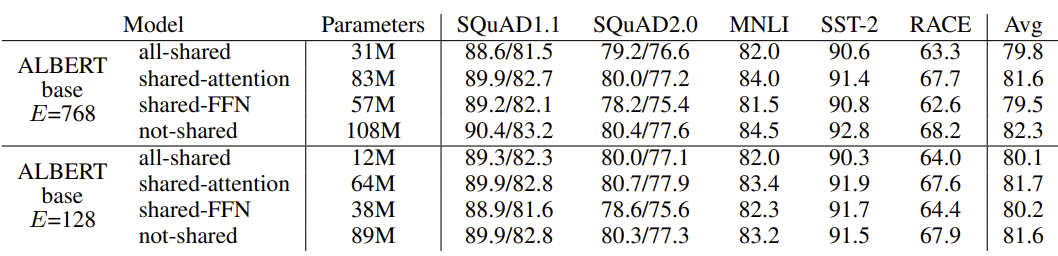
위와 동일하게 E는 vocabulary embedding size를 의미한다. E가 768인 경우와 128인 경우 모두 모든 parameter를 공유했을 때 성능이 낮아진다. 하지만 E가 128인 경우에 낮아지는 정도가 작다. 각 layer마다 parameter를 공유하는 다른 방법도 존재한다. 총 L개의 layer를 각각 M개의 layer로 구성된 N개의 그룹으로 나누는 것이다. 그룹 size인 M이 작을수록 성능이 높다. 하지만 M을 줄이면 전체 parameter 수가 증가하기 때문에 위 논문에서는 모든 layer의 parameter를 공유하는 방법을 사용한다.
Sentence-Order Prediction (SOP)
BERT 모델에서는 사전 훈련 과정에서 MLM(Masked Language Model) 작업과 NSP(Next Sentence Prediction) 작업을 한다. NSP 작업은 문장 간의 연결성을 학습하는 것을 목표로 하며, 특히 natural language inference와 같은 downstream 작업에서 성능을 향상시키기 위해 도입되었다. 하지만 후속 연구에서 NSP 작업의 효과가 제한적이라는 것이 밝혀졌다. 그리고 위 논문에서는 그 이유를 NSP 작업이 MLM 작업에 비해 너무 쉽기 때문이라고 추측했다. NSP 작업의 목표를 크게 두 가지로 나눌 수 있다. Topic prediction과 문장 간 연결성을 배우는 coherence prediction이다. 그런데 topic prediction은 coherence prediction에 비해 쉽다. 그리고 topic prediction은 MLM 작업에서도 충분히 학습할 수 있다. 따라서 ALBERT 모델에서는 NSP 작업 대신 coherence prediction에만 집중한 SOP 작업을 제안한다. SOP 작업은 ALBERT 모델에서 도입한 self-supervised 목표 중 하나이다. SOP 작업에서는 두 개의 연속적인 문장을 무작위로 순서를 바꾼다. 그리고 모델은 이 두 문장의 순서가 올바른지 혹은 바뀐 순서인지 예측한다.

Intrinsic task를 보면 NSP 작업을 사용한 모델은 SOP 작업을 잘 하지 못한다. 오히려 NSP 작업을 사용하지 않은 모델과 성능이 비슷하다. 그러나 SOP 작업을 사용한 모델은 NSP 작업을 잘 해낸다. 그리고 downstream task를 보면 NSP 작업 대신 SOP 작업을 사용했을 때 대부분 성능이 더 좋다.
Discussion
ALBERT_xxlarge 모델은 BERT_large에 비해 parameter 수가 훨씬 적고 성능이 좋지만 structure 자체가 너무 크기 때문에 computationally expensive하다. 그래서 ALBERT 모델의 training speed를 높이는 방법에 대한 후속 연구가 진행될 필요성이 있다.
paper