Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
Chain-of-Thought Prompting
: 대규모 언어 모델에게 주어진 문제에 대해 중간 단계의 추론을 거쳐 답변을 제시하도록 유도하는 prompting 기법이다. 언어 모델에게 단순히 정답을 말하라고 요구하는 것이 아니라 문제를 풀어가는 과정에서 발생하는 연속적인 사고 과정을 서술하도록 요청한다. 이 방식으로 인공지능은 더 복잡한 문제를 해결하고, 그 해결 과정을 인간이 이해할 수 있게 한다. 즉 모델이 더 투명하고 해석 가능한 방식으로 문제를 해결할 수 있게 한다.
A few chain of thought demonstrations are provided as exemplars in prompting.
이 문장에서 exemplar란 모델이 추론할 때 사용할 수 있는 예시이다 .즉 언어 모델에 문제를 제시할 때 추론 과정을 거쳐 답변을 도출하도록 특별히 설계된 prompt를 사용한다는 것이다.

위 그림에서 알 수 있듯이 prompt는 input, chain-of-thought, output으로 이루어져 있다.
CoT 기법을 사용했을 때 수학 문제를 푸는 것과 같은 복잡한 문제 해결 task에서 성능이 좋게 나왔다. GSM8K 데이터셋은 8000개 이상의 수학 문제를 포함하는 데이터셋이다. 모델은 특정 수학 문제를 해결하기 위해서 단계적 추론 과정을 보여주는 8개의 예제를 받아서 학습한 후 GSM8K 데이터셋 수학 문제들에 대한 답변을 제공했다. 결과적으로 fine-tuning된 GPT-3과 검증기를 사용한 것보다 우수한 성능을 나타냈다. 여기서 검증기란 오답을 걸러내는 기능을 가진 검증기를 말한다.
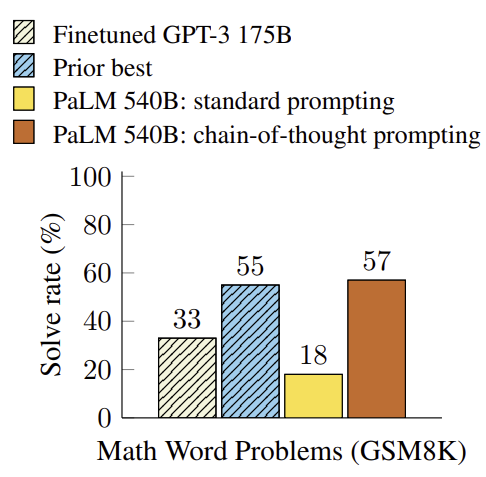
그래프를 보면 CoT 기법을 사용한 PaLM 540B 모델이 state-of-the-art를 달성했다. PaLM 540B는 Google Research에서 개발한 5400억 개의 parameter를 가진 대규모 언어 모델이다. 이 모델은 다음 개념들을 사용하고 있다.
- Prompting Only Approach: 추가적인 학습 데이터셋이나 모델의 fine-tuning 없이도 단순히 올바른 형태의 질문이나 문제를 제시함으로써 작업을 수행했다. 따라서 대규모의 학습 데이터셋이 필요하지 않고, 모델이 한 분야에 특화되지 않고 여러 작업을 수행할 수 있다.
- In-context Learning: 새로운 예제나 데이터를 별도의 학습 단계 없이 주어진 입력 문맥을 통해 즉시 이해하고 학습하는 능력이 있다.
- Few-Shot Learning: 많은 양의 데이터 없이도 소수의 예제만을 보고 새로운 작업을 수행할 수 있다.
Properties of Chain-of-Thought Prompting
- 모델이 multi-step 문제를 중간 단계로 분해하여 해결할 수 있게 한다. 모델은 문제의 각 부분을 차례로 해결하면서 최종 결론으로 나아간다. 이때 모델은 이러한 중간 단계를 처리하기 위해서 더 많은 계산 resource를 사용한다. 어떤 문제들은 간단하게 해결될 수 있지만 어떤 문제들은 여러 추론 단계를 필요로 하며 더 많은 계산이 요구된다. 이렇게 추가적인 계산 resource를 할당할 수 있기 때문에 모델은 더 복잡한 문제를 처리할 때 유리하다.
- 모델이 특정 답변에 어떻게 도달했는지 설명할 수 있고, 추론 과정에서 오류가 발생했을 때 그 오류를 debugging할 기회가 주어진다.
- 수학 문제와 같은 작업에 사용 가능하다.
- 충분히 큰 pre-training된 언어 모델에 chain-of-thought를 포함한 prompt를 사용함으로써 쉽게 chain-of-thought 추론을 유도할 수 있다.
Experiment
먼저 baseline으로 standard few-shot prompting을 사용하였다. 언어 모델을 학습시키기 위한 exemplar는 question과 answer로 이루어져 있다. 그리고 chain-of-thought prompting에서는 8개의 예시를 만들었다. 각각에 대한 답변과 함께 답변에 이르게 된 추론 과정을 추가하여 prompt를 보강한 것이다. 모델이 학습할 때 사용한 예시가 8개라는 것은 매우 작은 수이다. 모델이 추론하는 방법을 배우도록 하는 것이 목표이기 때문에 전통적인 기계 학습 접근법과 다르다. 이 기법을 다섯 가지 큰 언어 모델(GPT-3, LaMDA, PaLM, UL2 20B, Codex)에 적용해서 성능을 측정했다.
Result
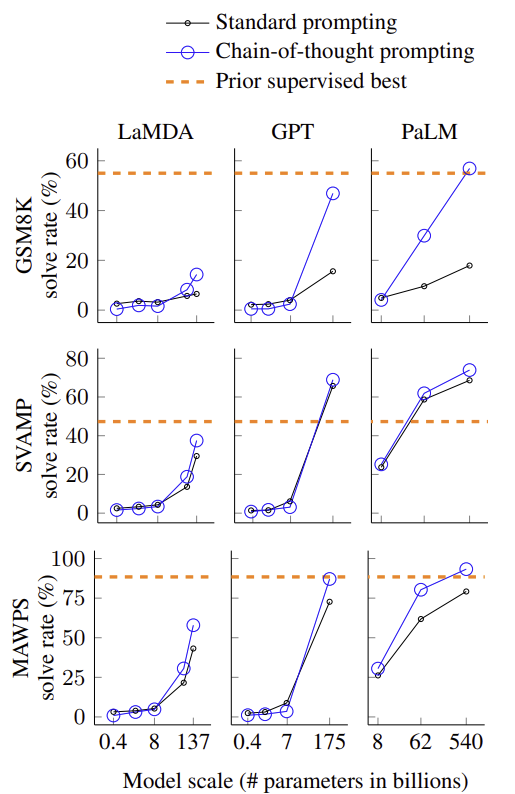
- 작은 모델에서는 성능이 향상을 보이지 않는다. 비논리적인 추론 과정을 생성하여 오히려 standard prompting보다 성능이 낮다. 대략 100B parameter를 가진 큰 모델들을 사용할 때만 성능 향상을 보인.
- Chain-of-thought prompting은 복잡한 문제에서 큰 성능 향상을 보인다. MAWPS의 SingleOp는 한 단계의 step만을 필요로 하는 쉬운 작업에서는 성능이 오히려 더 떨어지거나 성능 향상 정도가 매우 작았다.
- Label이 있고 특정 작업에 대해 fine-tuning하는 기술들이 달성한 기존의 state-of-the-art보다 chain-of-thought prompting을 사용한 모델이 더 유리하다.
오답 sample 50개를 무작위로 추출하여 조사했다. 사소한 오류들을 제외하고 46%의 chain-of-thought는 거의 정확했으며 54%의 chain-of-thought는 의미 이해에서 큰 오류를 범하고 있었다. 모델의 규모를 PaLM 64B에서 PaLM 540B로 규모를 확장했더니 의미 이해 오류를 많이 해결할 수 있었다. 즉 모델의 크기를 확장하여 parameter 수를 늘림으로써 모델이 더 정확한 추론을 할 수 있다는 것이다.
Ablation Study
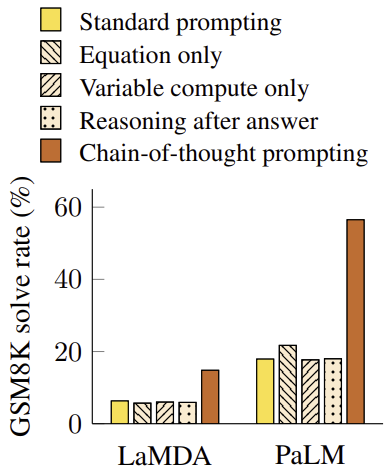
성능 향상의 원인이 사고 과정을 학습하기 때문이 아니라 이 세 가지 이유 때문일 수 있다.
- 수학 수식을 생성하기 때문: 모델이 답을 제시하기 전에 자연어 추론 단계 없이 수식만을 출력하도록 prompt를 변형시켰다. 결론은 아니었다. GSM8K 데이터셋에서 질문이 자연어 추론 단계 없이 직접 수식으로 변환하기에는 너무 어려웠다. 하지만 한 단계나 두 단계로 이루어진 쉬운 문제로 이루어진 데이터셋의 경우에는 질문으로부터 수식을 잘 도출해냈다.
- 어려운 문제에 더 많은 computation을 할당하기 때문: 모델은 문제 난이도에 따라서 다른 양의 계산을 수행하게 한다. 따라서 실험에서 모델이 문제를 풀기 위해 필요한 변수 수와 같은 수의 점(…)을 출력하도록 prompting을 변경하였다. 즉 모델이 실제 추론 과정을 수행하지 않고 추론 과정에 해당하는 길이만큼의 출력을 생성하도록 한 것이다. 하지만 baseline과 비슷한 성능을 보여주었다. 단순히 문제에 더 많은 계산을 할당하기 때문이 아니라는 것이다. 성능 향상이 단순히 모델이 더 많은 token을 사용하기 때문이 아니라 중간 추론 단계를 표현하는 과정 자체가 문제 해결에 도움을 준다는 것을 의미한다.
- 추론 과정이 단순히 모델이 pre-training 중 습득한 지식을 활성화하는 데 도움을 주기 때문: 모델에게 답변을 주고 나서야 chain-of-thought을 제시하는 실험을 한다. 하지만 성능이 baseline과 비슷하게 나왔다. Chain-of-thought이 단순히 지식을 활성화하는 역할을 넘어서 문제 해결 과정에서 중요한 역할을 한다는 것이다.
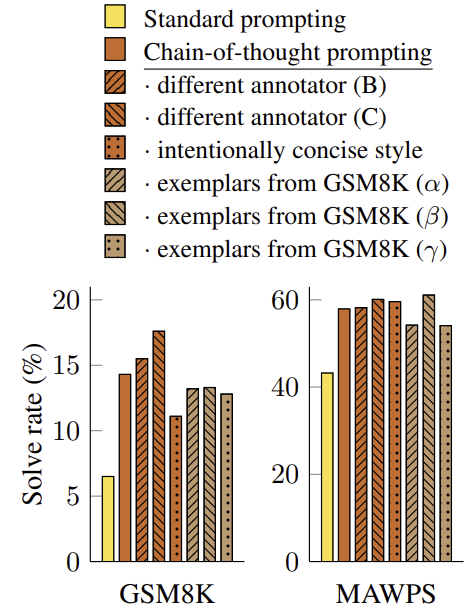
Robustness of Chain-of-Thought
Exemplar에 대한 민감도는 중요하다. 예를 들어 few-shot learning에서 exemplar의 순서를 변경하면 정확도가 54.3%에서부터 93.4%까지 바뀔 수 있다. 따라서 서로 다른 주석자가 chain-of-thought을 작성하게 하여 실험을 했다. 결과적으로 성능의 차이가 별로 보이지 않았고, 이는 chain-of-thought 기법이 특정 언어 style에 의존하지 않는다는 것을 의미한다. 그리고 다른 exemplar을 썼을 때, examplar의 순서를 다르게 했을 때, exemplar의 개수를 다르게 했을 때에도 성능이 모두 비슷했다.
Through experiments on arithmetic, symbolic, and commonsense reasoning, we find that chain-of-thought reasoning is an emergent property of model scale that allows sufficiently large language models to perform reasoning tasks that otherwise have flat scaling curves.
모델이 일정 규모 이상으로 커지면 이전에는 보이지 않았던 새로운 특성이 나타날 수 있다. 즉 모델이 매우 크면 chain-of-thought과 같은 새로운 방식을 개발할 수 있는데 이것은 모델이 작을 때는 나타나지 않던 특성이다. 모델의 크기를 늘려도 성능이 거의 향상되지 않는 상태를 flat scaling curve라고 한다. 즉 모델의 크기를 증가시키는 것만으로는 성능 향상에 한계가 있다는 것이다. 이 chain-of-thought을 통해서 이 한계를 넘어서 성능을 향상시킬 수 있다. 결론적으로 모델이 충분히 크디면 이전에는 성능이 정체되었던 영역에서도 복잡한 추론 작업을 할 수 있는 능력을 발달시킬 수 있다.
paper