Large Language Models are Zero-Shot Reasoners
LLM은 몇 가지 예시만으로 새로운 작업을 학습하고 수행할 수 있는 few-shot learners이다. 그리고 최근에는 CoT prompting 기법으로 어려운 추론 과정을 요하는 system-2 작업을 수행해내는 것까지 발전이 이루어졌다. 여기서 system-2 작업은 빠르고 직관적이며 노력을 거의 필요로 하지 않는 system-1 작업과는 달리 더 느리고 논리적이며 의식적인 주의를 필요로 하는 복잡한 작업을 말한다. 이 논문에서는 “Let’s think step by step”이라는 단순한 prompt를 추가함으로써 LLM이 꽤 괜찮은 zero-shot reasoners가 될 수 있음을 보인다. 이러한 단일한 template은 다양한 추론 작업에 걸쳐 유연하게 적용될 수 있어 높은 범용성을 드러낸다.
Zero-shot Chain-of-Thought
기존의 CoT prompting과는 달리 단계별 few-shot 예시를 필요로 하지 않는다. 그래서 특정 작업에 구애받지 않고 단일 template을 써서 광범위한 과제에 걸쳐 다단계 추론을 이끌어낸다. 이 zero-shot CoT는 두 단계의 prompting으로 이루어진다. 반면 few-shot CoT는 몇 가지 예시를 신중하게 설계해내는 인간의 노력이 필요하다.
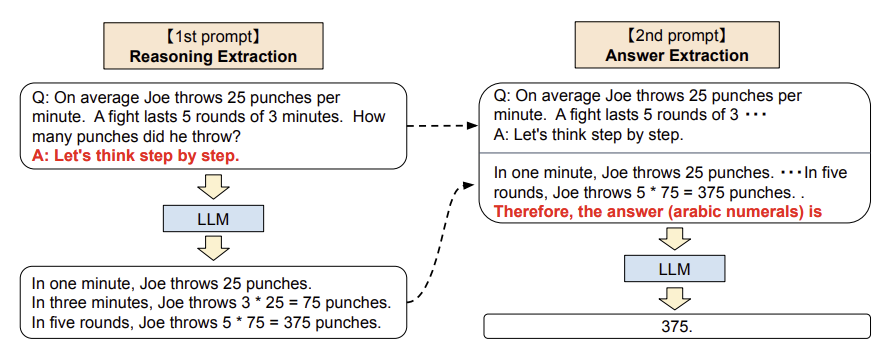
첫 번째 단계에서는 input question을 trigger 문장을 통해 수정한다. 예를 들어 “Let’s think step by step”이라는 trigger 문장을 통해 chain-of-thought을 이끌어낸다. 두 번째 단계에서는 첫 번째 단계에서 생성된 chain-of-thought을 사용하여 새로운 prompt를 만든다. 이 prompt는 원래 input question, 앞선 단계에서 생성한 chain-of-thought, 그리고 답변을 이끌어내는 또 다른 trigger 문장, 이렇게 세 가지로 이루어진다. 위 예시에서는 수학 문제에 대한 답변을 이끌어내기 위해서 “Therefore, the answer (arabic numerals) is”라는 trigger 문장을 사용했다. 작업 종류에 따라 trigger 문장은 달라질 수 있다.
Experiment
수학 문제, commonsense reasoning, symbolic reasoning 등으로 이루어진 12개의 데이터셋으로 모델의 성능을 측정하였다. 그리고 zero-shot-CoT prompting 기법을 17개의 모델에 적용하였다. 그리고 CoT를 사용하지 않은 zero-shot prompting 기법, few-shot 기법, few-shot-CoT 기법을 사용했을 때와 비교하였다. 이때 few-shot 기법은 사용하는 예시 순서에 따라 모델 성능에 영향을 주기 때문에 고정된 seed를 사용했다. CoT 기법을 사용했을 때에는 사용하는 예시 순서에 따라 모델 성능이 달라지지 않는다고 알려져 있다.

Result
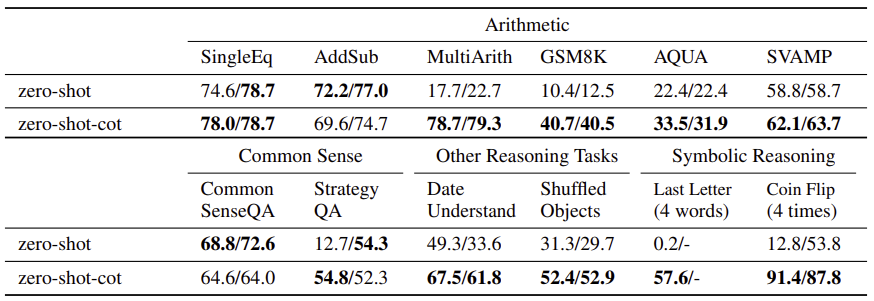
Zero-shot 기법을 사용했을 때와 비교해보면 zero-shot-CoT는 수학 문제 부분에서 6개 중 4개 작업에 대해 우수한 성능을 보인다. 다른 추론 작업이나 symbolic 추론 부분에서는 zero-shot-CoT가 모든 작업에서 zero-shot 기법을 사용했을 때 성능을 능가했다. 하지만 commonsense 추론 작업에 대해서는 zero-shot 기법보다 성능이 떨어졌다. 그런데 LLM이 생성한 chain-of-thought은 놀랍도록 논리적으로 정확했고 오류가 있다고 하더라도 사람이 이해할 수 있는 범위의 실수 정도였다. 이것은 zero-shot-CoT가 실제 작업의 평가 척도에 직접적으로 반영되지 않았을지라도 추론 능력을 개선하는 데 도움이 될 수 있다.
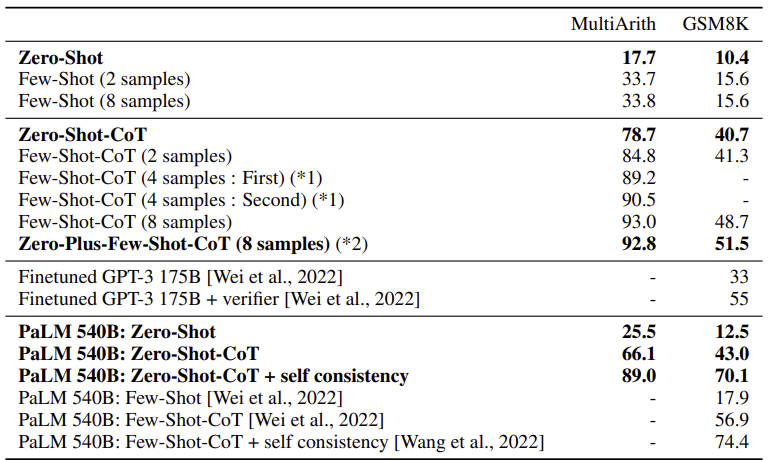
CoT prompting 기법을 사용했을 때와 사용하지 않았을 때를 비교해보면 성능 차이가 꽤 많이 난다. 다단계의 사고 과정을 요하는 어려운 작업에서는 CoT가 필수적이라는 것을 뜻한다. 당연히 zero-shot-CoT는 few-shot-CoT보다 성능이 떨어진다. 하지만 8개의 예시를 사용한 few-shot에서보다 zero-shot-CoT는 훨씬 높은 성능을 보였다. 그리고 fine-tuning된 GPT-3보다도 성능이 뛰어나다.
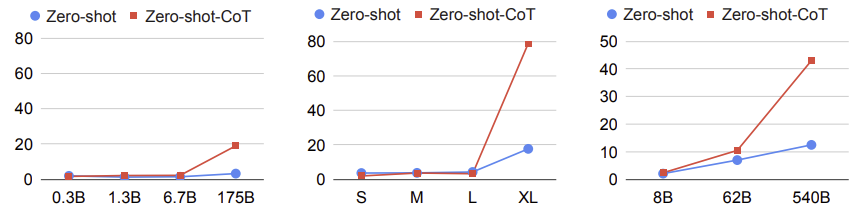
CoT prompting 기법을 사용하지 않았을 때에는 모델의 크기를 키워도 성능이 향상되지 않았다. 하지만 CoT prompting 기법을 사용하면 모델의 크기를 키울수록 성능이 급격하게 향상된다. 즉 모델이 작으면 CoT prompting 기법이 효과적이지 않다.
Prompt Selection
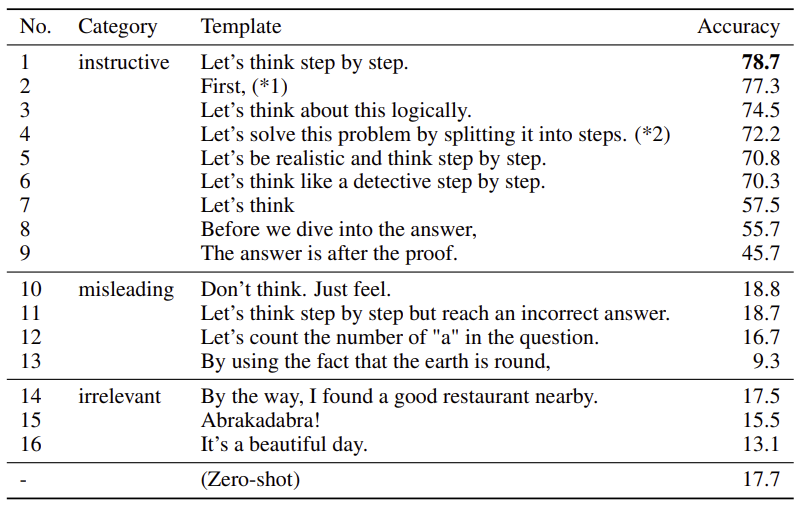
16개의 서로 다른 template을 가지고 모델의 성능을 측정하였다. Chain-of-Thought을 이끌어내는 9개의 문장을 썼을 때에는 작업을 잘 수행해낸다. 하지만 misleading 문장이나 아예 관련이 없는 문장을 trigger 문장으로 썼을 때는 성능이 형편없다. 9개의 문장 중에서는 “Let’s think step by step”이라는 trigger 문장이 제일 성능이 높게 나왔다.
Summary
이 논문에서는 LLM을 활용하여 복잡한 다단계 추론을 수행해내는 zero-shot-CoT 기법을 제안한다. Few-shot-CoT 기법에서는 사람이 prompt를 신중하게 설계해야 한다. 하지만 zero-shot-CoT 기법은 예시를 설계할 필요가 없고 “Let’s think step by step”과 같은 단순한 prompt를 통해 다양한 작업에 적용이 가능하다는 점에서 이점이 있다.
paper