Program of Thoughts Prompting: Disentangling Computation from Reasoning for Numerical Reasoning Tasks
Chain-of-Thought(CoT)는 언어 모델을 사용하여 문제에 대한 추론 과정을 text로 서술한다. 즉 문제를 해결하기 위한 단계별 추론 과정을 자연어로 설명한다. 모델은 문제의 각 단계에서의 생각을 연결해서 최종 답변을 도출한다. 반면 이 논문에서 제시한 Program-of-Thought(PoT)도 언어 모델을 사용하지만 복잡한 computation을 추론과 언어 이해로부터 분리한다. 즉 추론과 언어 이해는 언어 모델이 담당하고, 복잡한 computation은 program interpreter에서 실행한다. 이로써 언어 모델이 추론과 언어 이해에 더 집중할 수 있게 하고, 복잡한 computation은 더 효율적으로 처리된다. 결과적으로 PoT는 CoT에 비해 평균적으로 12%의 성능 개선을 보였다.

CoT는 LLM에게 추론과 계산(computation)을 모두 시킨다. 즉 LLM은 수식을 생성하고 그 계산까지 해야 한다. 하지만 LLM은 수식을 푸는 데에는 적합하지 않다. 이러한 한계는 LLM이 언어 처리에 중점을 두고 설계되었기 때문에 발생한다.
- 산술 계산 오류에 취약: 특히 큰 숫자를 다룰 때 오류를 범하기 쉽다. 이는 언어 모델이 정밀한 계산보다는 언어 이해와 생성에 최적화되어 있기 때문이다.
- 복잡한 수학 표현식 해결 능력 부족: 다항식 방정식이나 미분 방정식과 같은 복잡한 수학 표현식을 해결하는 데 적합하지 않다.
- 반복 표현의 비효율성: 반복(iteration)을 표현하는 데 적합하지 않다. 특히 반복 단계의 수가 많을 때 더욱 그렇다.
자연어 외에도 프로그램은 사고 과정을 표현하는 수단으로 사용될 수 있다. 의미 있는 변수명을 사용하면 된다. 예를 들어 위의 그림에서 미지수 이름을 interest_rate라 했다. 이것을 ‘sum_in_two_years_with_simple_interest’ 변수와 ‘sum_in_two_years_with_compount_interest’ 변수와 연결하여 수학 방정식을 작성한다. 이 방정식은 SymPy 라이브러리의 solve 함수로 Python을 통해 실행된다. PoT는 solve(20000 ∗ (1 + x) ^ 3 − 2000 − x ∗ 20000 ∗ 3 − 1000, x)와 같이 직접 방정식을 생성하는 것과는 다르다. 이렇게 직접적인 방정식 생성은 LLM에게는 어려운 작업이다. 따라서 PoT는 (1) 방정식을 여러 단계의 사고 과정으로 분해하고 (2) 변수에 의미를 부여한다. 이로써 언어 모델의 추론 능력을 끌어내고 더 정확한 프로그램을 생성한다.
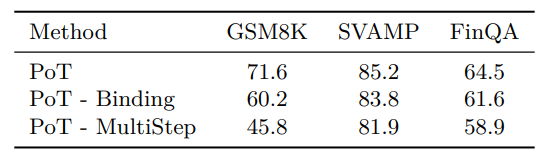
이 표는 (2) 의미 있는 이름의 변수를 사용하지 않고 단순히 a, b, c와 같은 변수를 사용했을 때 (- Binding) (1) 여러 단계의 사고 과정으로 분해하지 않고 단순히 방정식을 예측하게 했을 때 (- MultiStep)에 대한 ablation study이다. 의미 없는 변수를 사용했을 때 성능이 떨어졌다. 그리고 단순히 방정식만을 예측하게 했을 때에도 성능이 떨어졌다.
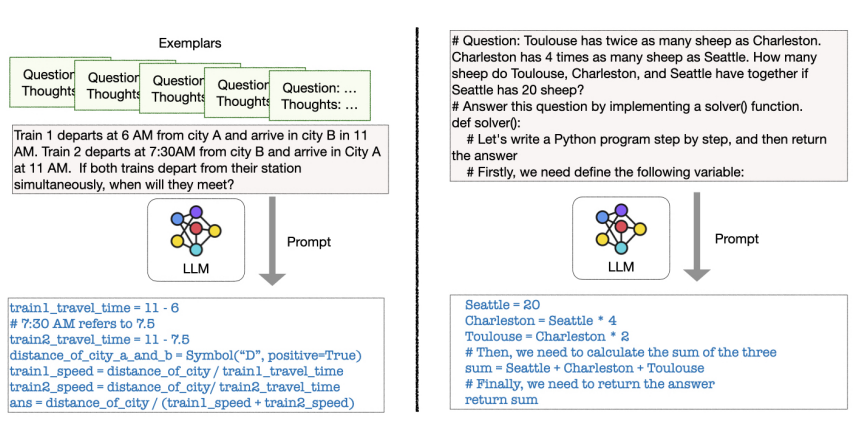
왼쪽은 few-shot setting이고 오른쪽은 zero-shot setting이다. Few-shot setting에서는 LLM에게 ‘thoughtful program’을 가르치기 위한 몇 가지 예제가 사용된다. 하지만 zero-shot setting에서는 어떠한 예제도 필요하지 않다. Zero-shot-CoT에서 최종 답변을 얻기 위해서는 모델이 생성한 일련의 추론 단계에서 답변을 추출하는 추가적인 작업이 필요하다. 즉 추론 과정에서 최종 결론을 찾아내는 과정을 필요로 한다. 하지만 zero-shot-PoT의 경우 zero-shot-CoT와는 다르게 program을 직접 생성하고 실행하여 바로 답변을 제공한다. 더 직접적이고 효율적이라고 할 수 있다. 그런데 zero-shot-PoT setting에서는 LLM이 실행 가능한 코드 대신 ‘#’ 기호로 시작하는 주석 형태로 추론 과정을 기술하려는 경향이 있을 수 있다. 이 문제를 해결하기 위해서 ‘#’ 토큰의 logit(모델이 각 토큰에 대해서 예측하는 점수)을 억제한다. 즉 모델이 ‘#’ 토큰을 생성할 확률을 인위적으로 낮춘다.
PoT as an Intermediate Step
특정 문제를 해결하기 위해서 PoT와 CoT를 결합하기도 한다. 즉 PoT를 사용해서 계산 부분을 처리하고 필요한 경우 CoT를 추가하여 텍스트 기반의 추론을 완성하여 최종 답변을 도출하는 방법이다. 복잡한 계산과 텍스트 추론이 모두 필요한 문제에 적합하다. 먼저 PoT를 사용하여 계산 부분을 처리한다. PoT에 의해 생성된 프로그램은 중간 결과를 제공하기 위해 실행되는 것이다. 생성된 중간 결과는 질문과 결합하여 CoT를 통해 최종 답변을 도출한다. 이때 LLM은 추가적인 CoT 추론이 필요한지 예측하도록 미리 교육을 받는다. 만약 LLM이 ‘keep prompting’을 출력하면 PoT의 실행 결과를 사용해서 CoT를 통해 답변을 도출한다. 예를 들어 위 figure의 왼쪽 예시를 보면 PoT를 통해 프로그램은 ans=2.05라는 소수점 숫자를 반환할 것이다. 두 기차가 2.05시간 후에 만난다는 것이다. 이제 오전 11시에 2.05시간을 더해야 한다. 이때 2.05시간을 분으로 변환하여 표준 HH:MM 시간 형식으로 만들어야 한다. 여기서는 CoT가 활용되는 것이다. 이러한 전략은 복잡한 수학 문제를 포함하는 AQuA 데이터셋에서만 필요하다. 다른 데이터셋에 대해서는 PoT만을 사용해서 해결할 수 있다.
Result
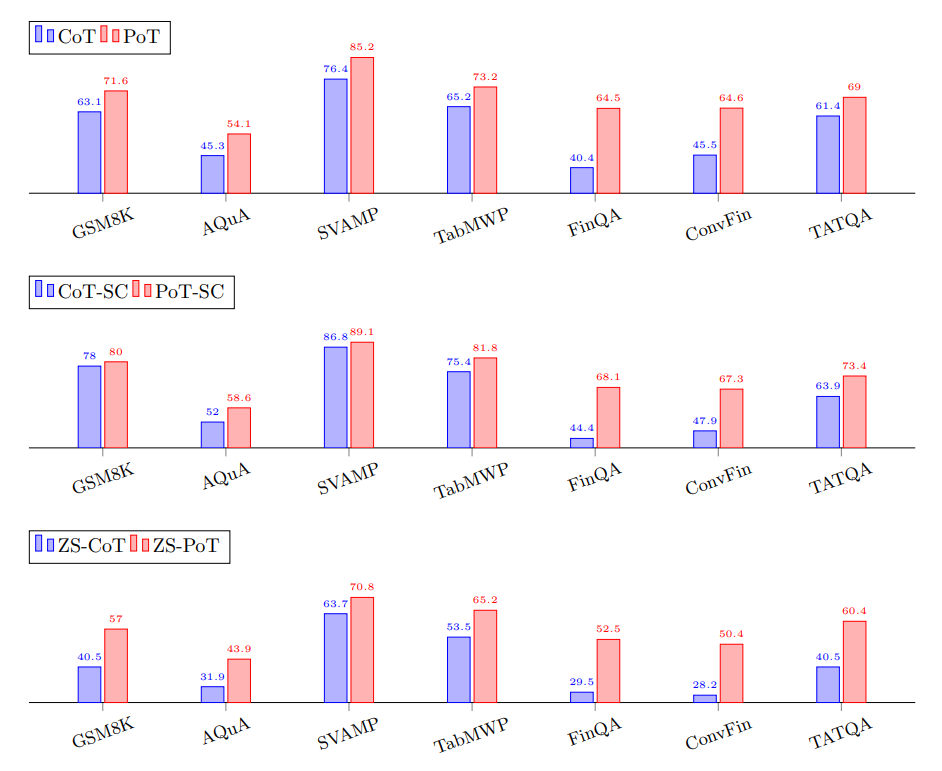
첫 번째에서는 few-shot (Greedy Decoding), 두 번째는 few-shot (Self-Consistency Decoding), 세 번째는 zero-shot이다. PoT가 CoT보다 높은 성능을 보인다.
Breakdown Analysis
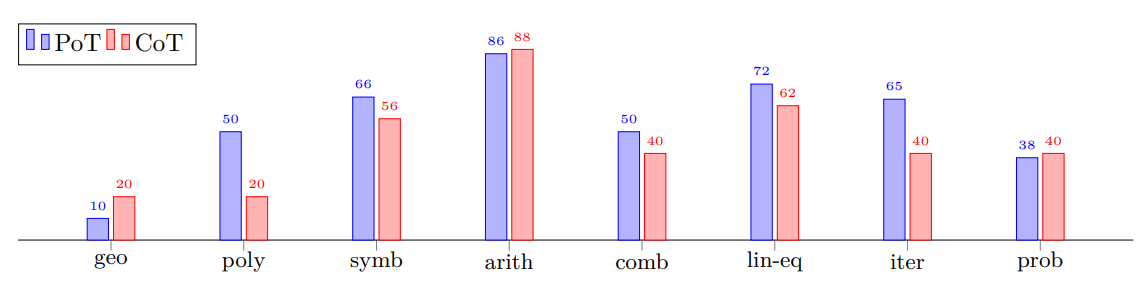
PoT와 CoT가 어떤 문제에서 가장 성능 차이를 보이는지 실험했다. AQuA 데이터셋을 여러 개의 종류(geometry, polynomial, symbolic, arithmetic, combinatorics, linear equation, iterative, probability 등)로 나누었다. 복잡한 계산을 요하는 linear/polynomial equation, iterative, symbolic, combinatorics에서는 PoT가 엄청난 성능 향상을 보였다. 하지만 arithmetic, probability, geometric에서는 CoT와 PoT가 성능이 비슷하다. 즉 PoT는 어려운 문제에서 효과를 나타낸다.
Limitation
PoT는 위험한 코드를 생성할 수 있다.
import os
os.rmdir()
예를 들어 위 코드는 중요한 파일이 저장된 directory를 삭제할 수 있다. 따라서 PoT는 LLM이 코드를 생성할 때 추가적인 module을 가져오는 것을 차단하고 사전에 정의된 module만을 사용하도록 제한하기도 한다. 이는 모델이 부적절한 코드를 생성하는 것을 방지할 수 있지만 PoT의 일반화 능력을 해칠 수 있다. 수학 문제 해결에서는 합리적으로 작동할 수 있지만 다른 작업에 대해서는 더 다양하고 유연한 방식으로 코드를 생성해야 하기 때문에 다양한 문제를 해결하는 데에는 적절하지 않다.
paper