Encouraging Divergent Thinking in Large Language Models through Multi-Agent Debate
Self-reflection은 LLM이 제시한 답변에 대해 스스로 피드백을 하고 답변을 수정하는 방법이다. 이는 LLM이 이전 답변과 그에 대해 스스로 내놓은 피드백을 바탕으로 새로운 답변을 반복적으로 제시하는 것을 의미한다. 하지만 이러한 방법은 Degeneration-of-Thought이라는 문제가 존재한다. 즉 LLM이 한 번 답변에 대해 확신을 가지게 되면 설령 그 답변이 잘못되었다 하더라도 새로운 방향으로 답변을 생성해내기 어렵다는 것이다. LLM의 자체 피드백 능력은 LLM 성능에 의해 크게 좌우되지만 이러한 능력은 올바르게 제공될 것이라는 공식적인 보장이 없다. 이 논문에서는 이러한 DoT 문제를 해결하기 위해 Multi-Agent Debate (MAD) 방법을 제안한다. 이 방법에서는 여러 에이전트가 “tit for tat” 상태에서 자신의 주장을 표현하고, 판사가 토론 과정을 관리하여 최종 해결책을 도출한다.
Once the LLM has established confidence in its answers, it is unable to generate novel thoughts later through self-reflection even if the initial stance is incorrect.
Degeneration-of-Thought의 원인에는 여러 가지가 있다.
- Bias and Distorted Perception: LLM은 편견, 선입견과 같은 왜곡된 사고 패턴으로부터 부정적인 영향을 받을 수 있다. 사전 훈련 과정에서 다량의 데이터를 학습하면서 이러한 사고 패턴을 배운 것이다. LLM의 자체 피드백이 이러한 편견이나 왜곡된 사고의 영향을 받으면 결국 부정확한 결론에 이를 수 밖에 없다.
- Rigidity and Resistance to Change: 자체 피드백은 자신의 믿음이나 가정에 도전하는 것이다. 만약 LLM이 변화에 저항하며 경직된 믿음을 가지고 있다면 더 나은 해결책으로 이어지는 의미 있는 자체 피드백에 도달하기 힘들다.
- Limited External Feedback: 자체 피드백은 LLM 스스로 하는 내부적인 과정이다. 이때 외부 피드백은 소중한 통찰력을 제공할 수 있다. 외부 피드백을 고려하지 않으면 LLM의 자체 피드백은 중요한 맹점을 놓치며 풍부한 답변을 생성할 수 없게 된다.
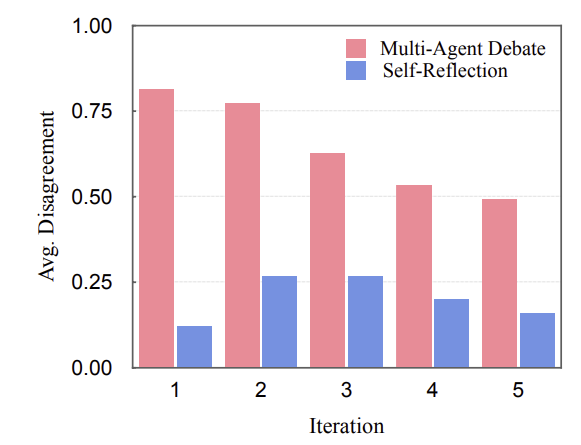
토론에서 두 토론자 간의 각 질문에 대한 반대 비율을 average disagreement라고 정의하였다. 위 그래프는 average disagreement를 계산하여 추세를 보여주었다. Self-Reflection 방법은 average disagreement가 낮다. 즉 Self-Reflection 방법은 잘못된 답변에 고착되어 있으며 의미 있는 자체 피드백을 주지 않는다는 것이다. MAD 방법이 Self-Reflection 방법보다 더 다양한 답변을 내놓는 것을 확인할 수 있다. MAD 방법은 Self-Reflection 방법와 비교할 때 다음과 같은 장점을 가진다.
- LLM의 왜곡된 사고는 다른 LLM에 의해 교정될 가능성이 있다.
- LLM의 변화에 대한 저항성은 다른 LLM에 의해 해소될 수 있다.
- 각 에이전트는 다른 에이전트들로부터 외부적인 피드백을 받을 수 있다. 이러한 이유로 MAD 방법은 Degeneration-of-Thought이라는 문제에 적은 민감성을 보인다.
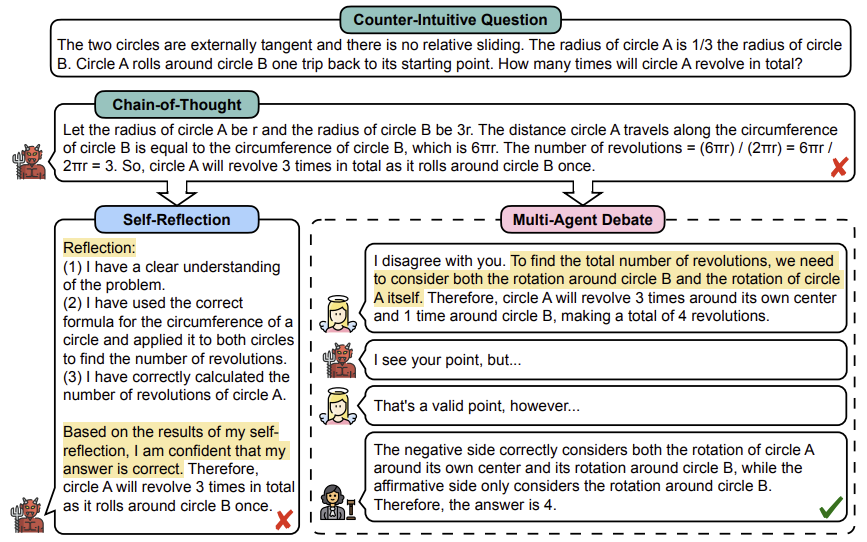
Contributions
- Self-Reflection 방법에서 Degeneration-of-Thought(DoT) 문제를 정의하고 Multi-Agent Debate(MAD)라는 해결책을 제시하였다.
- MAD 방법을 사용하면 backbone 모델로 GPT-3.5-Turbo를 사용했음에도 GPT-4보다 높은 성능을 보였다.
- 좋은 성능을 위해서는 토론에서 적응적인 중단 전략과 적당한 수준의 “tit for tat” 상태가 필요하다는 추가적인 분석을 제시하였다. 또한 서로 다른 LLM이 에이전트에 사용된다면 LLM이 공정한 판사 역할을 잘 하지 못한다는 것을 확인하였다.
Multi-Agent Debate Framework
다음 세 가지 주요 구성 요소로 이루어져 있다.
- Meta Prompts: 해결해야 할 주제를 제시하고, 토론자 수, 반복 횟수 제한 등을 메타 프롬프트로 설정한다.
- Debaters: N명의 토론자가 있으며 각 토론 반복마다 토론자 $D_i$는 정해진 순서대로 이전 토론 이력을 기반으로 하여 주장을 제시한다.
- Judge: 판사는 전체 토론 과정을 관리하고 감시한다. 두 가지 모드가 있다. 먼저 Discriminative 모드에서 판사는 모든 토론자의 의견을 듣고 올바른 해결책이 도출되었는지 판단한다. 해결책이 도출되었다고 판단되면 토론은 종료된다. Extractive 모드에서는 판사는 지금까지의 토론 이력을 바탕으로 최종 해결책을 도출한다. 이는 반복 횟수 제한에 도달했음에도 불구하고 올바른 해결첵에 도달하지 못했다고 판단되었기 때문이다.
두 가지 도전적인 과제에 대해 실험을 수행하였다.
- Common MT: MAD 방법은 GPT-3.5를 backbone 모델로 활용했을 때 인간이 평가한 지표와 COMET과 BLUERT와 같이 자동적으로 평가한 지표 모두에서 GPT-4보다 상당한 진전을 보였다.
- Counter-Intuitive AR: MAD 방법은 GPT-4만큼 좋은 성능을 보이지는 않았지만 GPT-3.5를 기반으로 한 다른 방법들보다 높은 성능을 보인다.
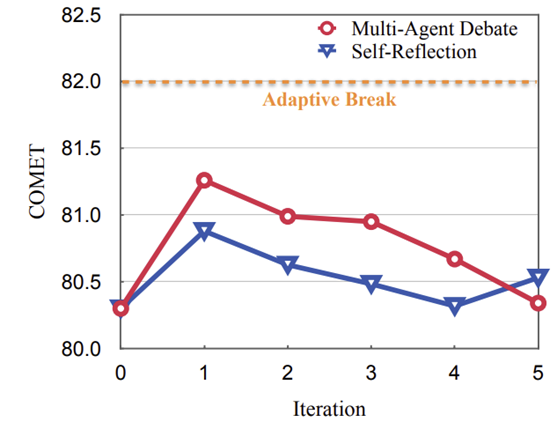
Effect of Adaptive Break
판사가 토론을 중단시키는 대신 최종 답변을 추출하도록 강제한 결과이다. 반복이 증가함에 따라 MAD 방법이 Self-Reflection 방법보다 더 나은 성능을 보인다. 그러나 가장 높은 COMET 점수는 첫 번째 반복에서 나타났다. 이는 대부분 첫 번째 반복에서 좋은 번역이 생성되었으므로 토론을 중단해야 한다는 것을 의미한다. 토론을 계속 진행하도록 강제하는 것은 번역 결과를 해칠 것이며 적응적 중단 전략의 타당성을 보여준다.
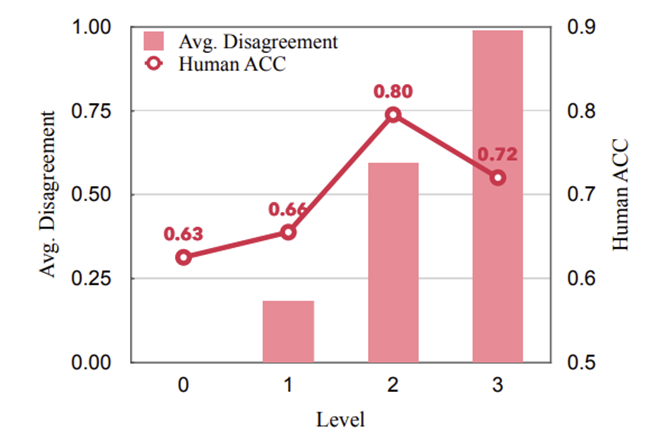

Essense of “Tit for Tat” State
“Tit for Tat” 상태의 강도가 MAD 방법의 성능에 어떤 영향을 미치는지 연구하였다. 토론자에게 서로 다른 답변을 내도록 하는 것은 MAD 방법이 좋은 성능을 달성하기 위해 필요하다. 하지만 항상 모든 점에서 동의하지 않도록 강제하면 오히려 성능이 저하된다는 것을 발견하였다. 지속적인 의견 불일치는 최종적인 해결책을 낸다는 목표를 달성하는 데 집중하지 못하고 양극화로 이어진다. 즉 진실이나 이해를 추구하는 토론보다 논쟁에서 이기는 것이 더 중요한 토론이 되어버린다.
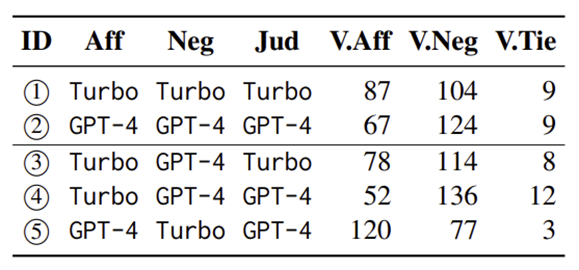
Behavior of Agents
위는 판사가 각 토론자의 답변을 최종 해결책으로 선택한 횟수를 나타냈다. 첫 번째 행과 두 번째 행을 비교했을 때 판사는 일관되게 부정적인 측면을 선호하는 것을 알 수 있다. 또한 세 번째 행과 네 번째 행을 비교했을 때 판사는 같은 backbone 모델을 사용한 LLM을 선호한다는 것을 알 수 있다. 네 번째 행과 다섯 번째 행을 비교했을 때에도 마찬가지이다. 이는 서로 다른 LLM이 에이전트로 사용될 때 LLM은 공정한 판사의 역할을 하지 못할 수 있음을 나타낸다.
paper