Improving Language Understanding by Generative Pre-Training
이 논문은 Generative Pre-Training (GPT)이라는 개념을 소개하고, 이 방법이 어떻게 언어 이해 능력을 개선하는지 설명한다. GPT는 큰 데이터셋에서 언어 모델을 사전 학습시키는 방법으로, 모델이 다양한 문맥과 언어 구조를 학습할 수 있게 한다. 이후, 특정한 작업이나 데이터셋에 대해 모델을 미세 조정한다.
Introduction
레이블이 있는 데이터의 부족과 레이블이 없는 데이터의 풍부함은 자연어 처리(NLP) 분야에서 중요한 도전 과제이다. 따라서 레이블이 없는 데이터로부터 언어 이해 능력을 학습하는 것은 필수적이며, 이전에는 주로 단어 수준(word-level)의 정보를 사용하는 방법이 있었다. 그러나 단어 수준을 넘어서는 정보를 활용하는 것에는 두 가지 주요한 문제가 있다. 첫째, 사전 훈련 단계에서 어떤 학습 방법이 가장 효과적인지 불분명하다. 둘째, 사전 훈련된 모델의 학습된 표현을 특정 작업에 어떻게 적용하고 적응시킬지에 대한 명확한 방법이 없다. 이러한 문제들에 대응하기 위해, 논문은 준지도 학습(semi-supervised) 접근 방법을 제안한다. 이 접근법은 먼저 레이블이 없는 데이터를 사용하여 모델의 초기 파라미터를 학습하고, 이후 레이블이 있는 데이터를 사용하여 target task로 이 파라미터들을 추가로 학습한다. 이 과정에서 모델 아키텍처로는 Transformer를 사용하는데, 이는 순환 네트워크(recurrent network)와 달리 장기적인 의존성(long-term dependency)을 효과적으로 처리할 수 있기 때문이다.
사전 훈련된 모델의 숨겨진 표현(hidden representations)을 보조 특징(auxiliary features)으로 사용
-
사전 훈련된 모델의 출력을 다른 모델의 입력으로 사용하는 방식: 사전 훈련된 모델을 고정시키고 그 출력을 다른 학습 모델의 입력으로 사용한다. 예를 들어 BERT의 출력을 특정 분류 작업을 수행하는 별도의 신경망의 입력으로 사용한다. 이 방법은 추가적인 파라미터를 도입해야 하고 target task에 따라 별도의 모델 구조를 설계하고 학습시켜야 한다.
-
미세 조정 방식: 사전 훈련된 모델을 기반으로 하여 특정 target task에 대해 추가 학습을 진행한다. 모델의 원래 가중치는 초기값으로 사용되며 target task의 데이터에 맞게 미세 조정된다. 이 방식은 모델 아키텍처를 크게 변경하지 않고 사전 훈련된 모델의 지식을 활용하여 target task에 적용할 수 있다.
Unsupervised Pre-Training
이 논문에서 제안한 구조는 멀티 레이어 Transformer 디코더를 기반으로 한다.
\[h_0 = U W_e + W_p\]각 토큰의 초기 context 벡터를 토큰 임베딩 행렬과 곱하고 위치 임베딩 행렬을 더함으로써 생성된다. 즉 각 토큰의 의미적 정보와 그 순서 정보를 결합하는 것이다.
\[h_l = \text{transformer_block}(h_{l-1}) \quad \forall i \in [1, n]\]여러 레이어에 걸쳐서 반복한다. 각 Transformer 블록 내에서는 multi-headed self-attention 연산과 position-wise feedworard 레이어를 포함한다. 이 과정에서 각 토큰이 전체 입력 시퀀스의 문맥을 고려하여 표현을 업데이트한다.
\[P(u) = \text{softmax} (h_n W_e^T)\]마지막 레이어의 출력을 토큰 임베딩의 전치와 곱하고 softmax를 취해 각 위치에서 다음 토큰의 확률 분포를 생성한다.
\[L_1(\mathcal{U}) = \sum_i log P(u_i | u_{i-k}, ..., u_{i-1} ; \Theta)\]이 likelihood를 최대화하도록 학습한다.
Supervised Fine-Tuning
\[P(y|x^1,..., x^m) = \text{softmax} (h_l^m W_Y)\]모델의 마지막 레이처 출력과 출력 임베딩 행렬 $W_y$의 곱에 softmax를 적용한다. 여기서 $h_l^m$은 Transformer 모델을 통과한 후의 최종 hidden state를 나타낸다. 이렇게 target 클래스 y에 대한 확률 분포를 생성한다.
\[L_2(\mathcal{C}) = \sum_{x, y} log P(y | x^1, ..., x^m)\]즉 이 likelihood를 최대화하는 것이다.
최종 목표 함수
\[L_3(\mathcal{C}) = L_2(\mathcal{C}) + \lambda * L_1(\mathcal{C})\]이 함수는 미세 조정 단계에서의 target task에 대한 손실과 사전 학습 단계의 언어 모델링 손실을 결합한 것이다. 여기서 $\lambda$는 두 손실 간의 균형을 조절하는 하이퍼파라미터이다. 이렇게 함으로써 모델은 target task에 대해 최적화하면서도 일반적인 언어 이해 능력을 유지할 수 있다. 이 목표 함수는 두 단계의 학습 과정을 연결하지만 실제로 사전 훈련과 미세 조정은 일반적으로 별도의 순차적 단계로 진행된다.
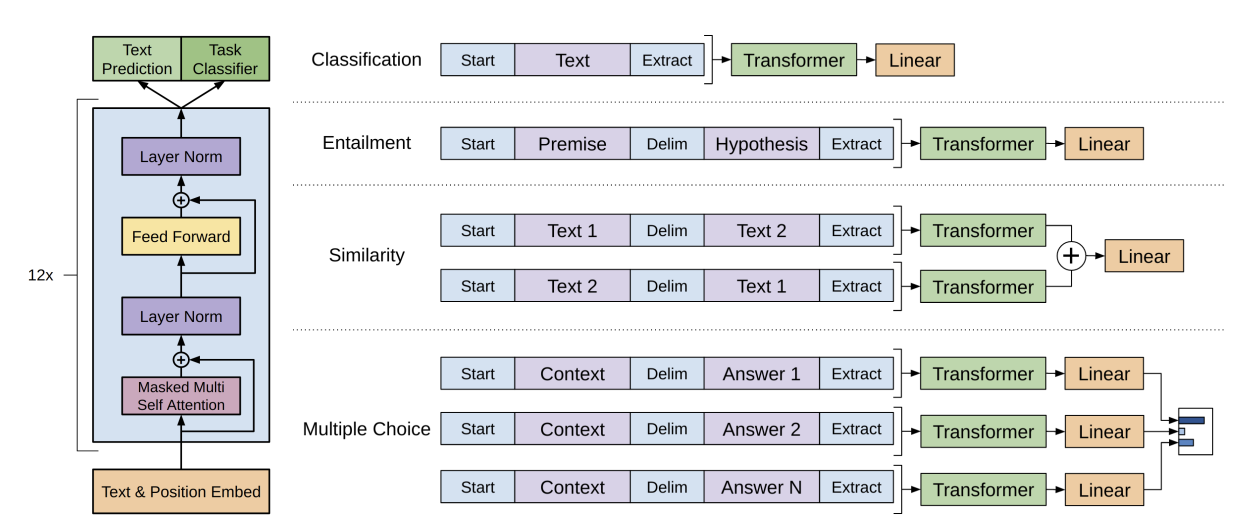
Task-Specific Input Transformations
텍스트 분류와 같은 일부 작업의 경우에는 입력이 단일 문장으로 이루어져 있어서 비교적 간단한 입력 구조를 가지고 있다. 하지만 질문 응답과 같은 작업은 ‘문서-질문-답변’처럼 입력이 구조화되어 있다. 이러한 복잡한 입력을 처리하기 위해 정렬된 시퀀스로 변환하는 ‘traversal-style’ 방식을 사용한다. 이는 구조화된 데이터를 모델이 처리할 수 있는 형태로 변환함으로써 다양한 작업에 모델을 적용할 수 있도록 한다. 이러한 입력 변환을 통해 모델의 아키텍처 변경을 최소화할 수 있다.
paper