Prefix-Tuning: Optimizing Continuous Prompts for Generation
Prefix-Tuning의 등장 배경
Fine-tuning 과정에서는 모든 파라미터를 업데이트해야 하기 때문에 모델의 전체 사본을 저장해야 한다. 그리고 이 과정은 상당한 계산 자원을 요구한다. 현재 언어 모델의 크기는 매우 크다. GPT-2는 7억 7천 4백만 개의 파라미터를 가지고 있으며 GPT-3은 1750억 개의 파라미터를 가진다. 이러한 대규모 언어 모델 사본을 저장하는 것은 경제적으로 부담이 된다. 이 한계를 극복하기 위한 방법으로 lightweight fine-tuning이라는 방법이 존재하긴 한다. 이 방법은 사전 훈련된 파라미터의 대부분을 고정시키고 모델에 학습 가능한 파라미터를 일부 추가한다. 예를 들어 adapter-tuning은 사전 훈련된 언어 모델의 레이어 사이에 task에 특화된 레이터를 추가한다. 이 방법을 사용했을 때 전체 파라미터의 2-4%만 추가하면서 사전 훈련된 언어 모델을 fine-tuning한 것과 비슷한 성능을 달성했다.
Prefix-Tuning에 대한 설명
Fine-tuning의 한계를 극복하기 위해 위 논문에서는 Prefix-Tuning이라는 방법을 제시한다. 이 접근법은 언어 모델의 파라미터를 고정시킨 채로 특정 task 맞춤 연속적인 벡터(continuous task-specific vectors)만을 최적화한다. 이 벡터들을 prefix라고 부르며 모델의 입력 부분에 추가되어 가상의 토큰처럼 작동한다. 즉 모델이 이후의 토큰들을 처리할 때 이 prefix를 마치 실제 토큰처럼 취급하여 해당 토큰들이 이 prefix에 attend하게 한다. 이로써 모델이 더 적은 계산 자원을 사용하면서도 효과적으로 작업을 수행할 수 있도록 도와준다. Prefix-tuning은 전체 파라미터의 단 0.1%만 학습해도 데이터가 많은 환경에서는 fine-tuning과 비슷한 성능을 보이며 데이터가 적은 환경에서는 더 우수한 성능을 나타낸다. 또한 훈련 중 보지 못한 새로운 주제의 예시들에 대해서 더 잘 일반화한다.
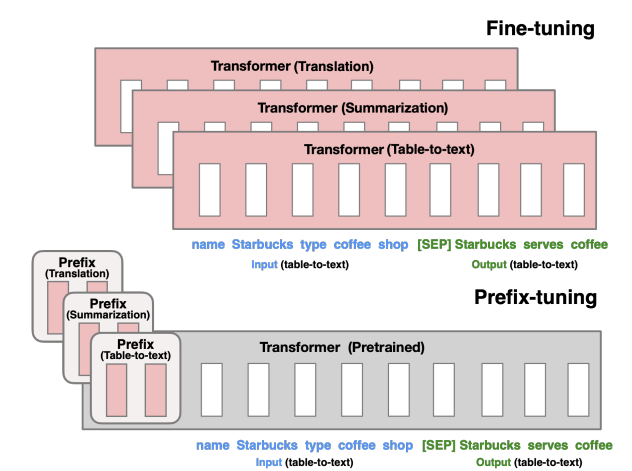
Prefix-tuning은 입력에 연속적인 task 맞춤 벡터(prefix)를 추가한다. 트랜스포머 모델은 이후 토큰들이 이 prefix를 가상의 토큰 시퀀스처럼 취급하여 attend할 수 있다. 여기서 주의할 점은 prefix는 실제 토큰에 해당하지 않는다는 것이다. Prefix는 언어 모델의 vocabulary에 포함한 실제 토큰에 직접적으로 대응되지 않는다. 즉 이 prefix에 해당되는 토큰을 모델의 vocabulary에서 찾을 수 없다. 전체 파라미터를 업데이트하는 fine-tuning과는 다르게 prefix-tuning은 prefix만을 최적화한다. 만약 감정 분석 task를 한다면 특정 prefix는 모델이 긍정 또는 부정적인 감정을 효과적으로 감지하도록 학습될 것이다. 학습 후 큰 트랜스포머 모델의 사본 한 개와 각각의 작업에 맞춤화된 prefix만을 저장하면 된다.
Prefix-tuning의 장점은 하나의 언어 모델이 여러 작업을 동시에 지원할 수 있게 한다는 것이다. 또한 개인 맞춤화된 작업을 위해 각 사용자에 해당하는 별도의 prefix를 사용할 수 있다. 예를 들어 개인화된 추천 시스템을 구축할 때 각 사용자의 과거 구매 기록, 검색 기록, 선호도 등을 고려하여 개별 prefix를 학습시킬 수 있다. 이를 통해 사용자별로 맞춤화된 추천을 생성할 수 있는 것이다. 또한 prefix-tuning은 여러 사용자나 task의 예시들을 동시에 하나의 batch에서 처리할 수 있게 한다. 이는 다른 lightweight fine-tuning 방법에서는 불가능했다. 전통적인 모델 훈련 방식에서는 각 task마다 별도로 처리해야 했다. 하나의 task를 위한 모델을 훈련시키고, 다른 task를 수행할 때에는 다른 모델을 사용하거나 동일 모델을 다시 훈련시켜야 했다. 시간과 자원이 많이 소모된다. 하지만 prefix-tuning을 사용하면 한 언어 모델에 대해 여러 개의 다른 prefix를 적용할 수 있다. 예를 들어 한 batch에서 감정 분석, 요약, 기계 번역 등 서로 다른 작업들에 대한 데이터를 함께 처리할 수 있다.
Intuition
적절한 맥락이 있으면 언어 모델의 파라미터를 변경하지 않고도 언어 모델을 원하는 방향으로 유도할 수 있다. 예를 들어 언어 모델가 Obama라는 단어를 생성하게 하고 싶다면 앞에 Barack을 추가함으로써 모델을 도울 수 있다. 그러나 이러한 적절한 맥락이 실제로 존재하고 찾을 수 있는지 명확하지 않다. 맥락에 사용될 적절한 단어나 토큰을 찾기 위해 vocabulary에 가능한 모든 조합을 탐색해야 하는데 이는 매우 많은 계산 자원을 필요로 한다. 그리고 모델의 vocabulary에 있는 단어만을 사용할 수 있기 때문에 항상 완벽한 맥락의 단어가 존재하는 것도 아니다. 따라서 prefix로 연속적인 벡터를 사용한다. 이렇게 최적화된 연속적인 prefix는 트랜스포머 구조 내 여러 활성화 레이어에 영향을 미친다.
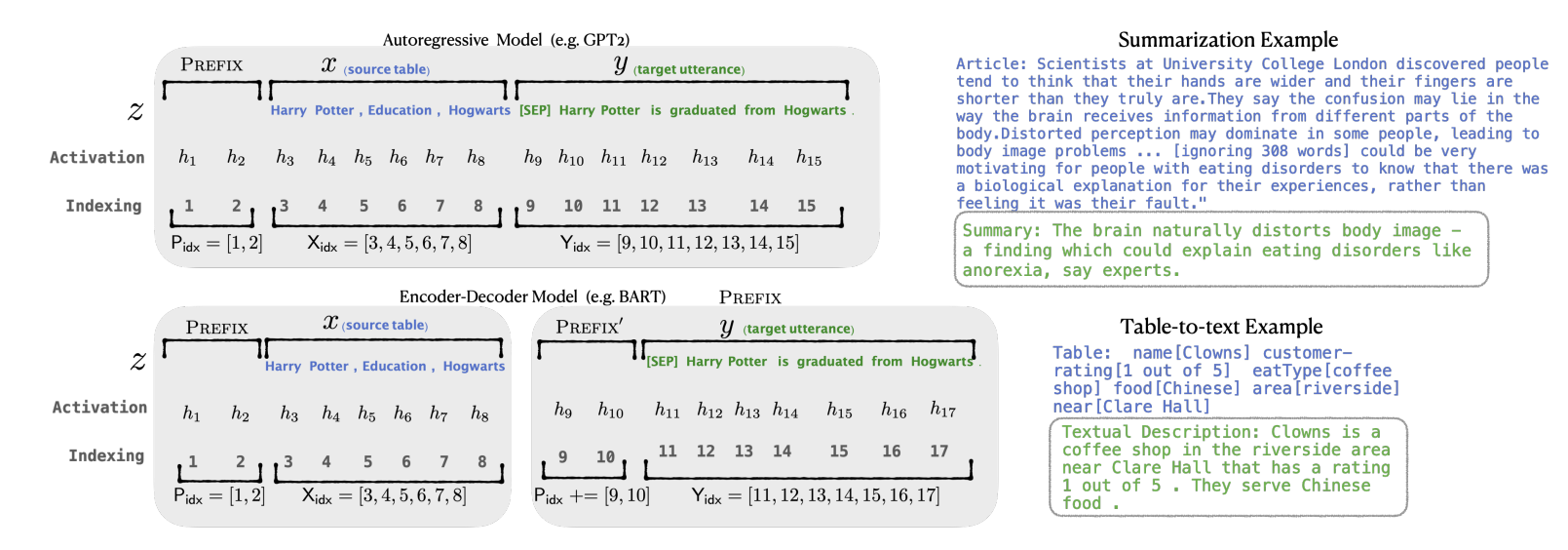
Method
먼저 입력에 prefix를 추가한다. 만약 autoregressive 언어 모델이라면 입력은 $z = [\text{PREFIX};x;y]$가 된다. 만약 인코더와 디코더가 모두 있는 언어 모델이라면 입력은 $z=[\text{PREFIX};x;\text{PREFIX}’;y]$가 된다. Prefix의 index를 $\text{P} _ \text{idx}$라고 한다. Prefix 파라미터는 행렬 $P_\theta$에 저장되어 학습되며 이 행렬의 차원은 $\vert \text{P} _ \text{idx} \vert \times \text{dim} (h_i)$이다. 언어 모델의 파라미터 $\phi$는 고정되고 prefix 파라미터인 $\theta$만이 학습된다. 그리고 $i$ 시점의 출력 $h_i$은 다음과 같다. 만약 prefix 부분에 속한다면 prefix 파라미터 행렬 $P_\theta$에서 직접 복사된다. 그렇지 않은 경우에는 이전 출력과 입력을 바탕으로 언어 모델에 의해 계산된다.
\[h_i = \begin{cases} P_\theta[i, :], & \text{if } i \in \text{P}_{\text{idx}} \\ LM_\phi(z_i, h_{<i}), & \text{otherwise} \end{cases}\]Prefix 파라미터를 직접 업데이트하는 것은 불안정하게 작동해서 성능이 약간 떨어진다고 한다. 이를 해결하기 위해서 $P_\theta[i, :] = \text{MLP} _ \theta (P’_ \theta [i, :] )$로 표현한다. 여기서 $P_\theta’$는 더 작은 행렬이다. $P_\theta$와 $P_\theta’$는 prefix의 길이가 같기 때문에 동일한 행의 개수를 가지지만 열의 차원은 다르다. 파라미터의 학습이 끝나면$P_\theta$만 저장된다.
paper