REALM: Retrieval-Augmented Language Model Pre-Training
이 논문에서는 언어 모델의 사전 학습(pre-training) 단계에 정보 검색 기능을 통합하는 새로운 접근 방식을 제시한다. 기존의 언어 모델들은 지식을 신경망의 파라미터 안에 저장하기 때문에 더 많은 정보를 담기 위해서는 모델의 규모를 크게 해야 한다. 또한 기존 언어 모델들은 지식을 신경망 파라미터에 암묵적으로 저장한다. 그래서 어떤 지식이 어디에 저장되어 있는지 명확하게 알 수 없다. 이는 지식의 출처를 추적하기 어렵게 만들며 모델의 해석성을 떨어트린다. 반면 REALM은 외부 지식을 실시간으로 검색하고, 그 검색 결과를 바탕으로 정보를 활용할 수 있는 능력을 갖추고 있다. 즉 모델이 새로운 데이터에 대해 예측을 하거나 결론을 도출할 때 어떤 지식을 활용할지, 그리고 그 지식을 위해 어떤 문서를 검색하고 참조할지를 명확히 알 수 있는 것이다. 예측하는 과정에서 언어 모델은 먼저 retriever를 통해 위키피디아와 같은 대규모 말뭉치에서 관련 문서를 검색한다. 그리고 이 문서들에 attend를 하면서 예측을 수행한다. 이를 통해 REALM은 모델 구조의 크기를 대폭 늘리지 않고도 풍부한 정보를 처리할 수 있다.
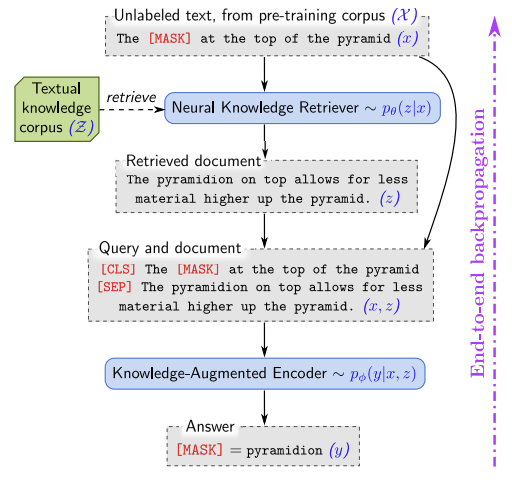
REALM은 사전 학습 과정에서 비지도 학습 방식을 사용하여 masked language modeling을 수행한다. 예를 들어 위 그림을 보면 “the [MASK] at the top of the pyramid”라는 문장에서 [MASK] 토큰을 채워야 한다. 이때 retriever는 “The pyramidion on top allows for less material higher up the pyramid.”라는 문서를 찾아내면 긍정적인 보상을 받는다. 언어 모델링에서 설정한 목표에 따라 얻은 결과는 retriever를 거쳐 다시 역전파된다. 이때 retriever는 $\mathcal{Z}$라는 방대한 문서 집합에서 수백만 개의 문서 중 도움이 되는 문서를 선택해야 한다. 그리고 이것은 엄청난 계산량을 요구한다.
REALM’s Generative Process
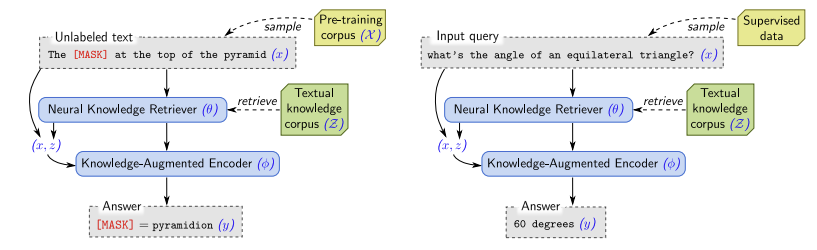
REALM은 사전 학습(pre-training)과 미세 조정(fine-tuning) 모든 단계에서 입력 $x$를 받아 출력 $y$에 대한 분포인 $p(y \vert x)$를 학습한다. 사전 학습 때에는 masked language modeling을 수행하게 된다. 여기서 $x$는 말뭉치 $\mathcal{X}$에서 일부 토큰이 masking된 문장이다. 모델은 이 masking된 토큰을 예측하게 된다. 미세 조정 단계에서는 Open-QA 작업을 수행하게 된다. 이때 $x$는 질문이고 $y$는 답변이 된다.
REALM은 $p(y \vert x)$를 두 단계(retrieve, predict)로 분해한다. 입력 $x$가 주어지면 (1) 말뭉치 $\mathcal{Z}$로부터 도움이 될 것 같은 문서 $z$를 검색한다. 즉 $p(z \vert x)$를 모델링한다. 그리고 (2) 검색된 $z$와 원본 입력 $x$를 기반으로 하여 출력 $y$를 생성한다. 즉 $p(y \vert z, x)$를 모델링한다. 최종적으로 $p(y \vert x)$를 얻기 위해서 $z$를 latent 변수로 취급하고 가능한 모든 문서 $z$에 대해 marginalize하여 $p(y \vert x) = \sum_{z \in \mathcal{Z}} p(y \vert z, x) p(z \vert x)$를 도출한다.
Model Architecture
-
Knowledge Retriever
먼저 retriever는 문서와 문장을 고정된 길이의 dense 벡터로 변환하고 이 벡터들 사이의 내적을 사용하여 유사성을 측정한다. 즉 각 문서나 문장은 고차원 공간에서 하나의 점으로 표현되며 이 점들 사이의 거리는 그들 사이의 의미적 유사성을 나타낸다.
\[f(x, z) = \text{embed} _ {\text{input}} (x)^T \text{embed} _ {\text{doc}} (z)\]그리고 유사성 점수 전체에 대해서 softmax 함수를 적용하여 retrieval 분포를 확률 값으로 변환한다.
\[p(z \vert x) = \frac{\text{exp} f(x, z)}{\sum_{z'} \text{exp} f(x, z')}\]이 과정은 BERT-style Transformer를 통해서 임베딩 함수로 구현한다. 먼저 WordPiece 토큰화를 적용한 후 두 텍스트 사이에 [SEP] 토큰을 둔다. 그리고 시작 부분에 [CLS] 토큰을, 끝 부분에 [SEP] 토큰을 추가한다.
\[\text{join} _ {\text{BERT}} (x)= \text{[CLS]} x \text{[CLS]}\] \[\text{join} _ {\text{BERT}} (x_1, x_2) = \text{[CLS]} x_1 \text{[SEP]} x_2 \text{[SEP]}\]이 데이터를 Transformer에 입력하면 시작 부분의 [CLS] 토큰을 포함한 모든 토큰이 하나의 벡터로 변환된다. 최종적으로 차원 축소를 위해서 linear projection을 수행한다. 이 과정을 통해 문서와 문장 간의 의미적 유사성을 효과적으로 측정할 수 있는 구조가 만들어진다.
\[\text{Embed} _ {\text{input}} (x) = W _ {\text{input}} \text{BERT} _ {\text{CLS}} (\text{join} _ {\text{BERT}} (x))\] \[\text{Embed} _ {\text{doc}} (z) = W _ {\text{doc}} \text{BERT} _ {\text{CLS}} (\text{join} _ {\text{BERT}} (z _ {\text{title}}, z _ {\text{body}}))\]
-
Knowledge-Augmented Encoder
입력 $x$와 검색된 문서 $z$가 함께 Transformer에 입력된다. 여기서 사용되는 Transformer는 retriever 부분에서 사용된 Transformer와는 다른 것이다. 이제 입력 $x$와 문서 $z$ 사이에서는 cross-attention이 이루어지며, 이 과정을 통해 최종 출력 $y$를 예측한다. 이 과정은 사전 학습 단계와 미세 조정 단계에서 각각 다르게 작동한다.
사전 학습 단계에서는 입력 $x$의 [MASK] 토큰을 예측하는 것이 목표이다. 그래서 masked language modeling에서와 동일한 손실 함수를 사용한다. 여기서 $J^x$는 입력 $x$ 내 [MASK] 토큰의 총 개수이고 $\text{BERT} _ {\text{MASK} (j)}$는 $j$번째 [MASK] 토큰에 대응하는 Transformer의 출력값을 나타낸다. 그리고 $w_j$는 예측해야 할 $y_j$ 토큰에 해당하는 학습된 임베딩 값이다. 사전 학습 과정에서 모델은 모든 단어 임베딩에 대해서 처음에 임의의 값으로 시작해서 학습이 진행됨에 따라 단어의 의미를 포착하는 벡터로 발전시킨다. 이는 입력 $x$, 문서 $z$, 그리고 예측 대상인 $y$에 대해서도 마찬가지다. 위에서 학습된 임베딩 값 $w_j$이라는 것은 특정 단계에서 모델이 이미 어느 정도 학습을 거치고 그 결과로 얻은 단어 임베딩을 사용한다는 것이다.
\[p(y \vert z, x) = \prod_{j = 1}^{J^x} p(y_j \vert z, x)\] \[p(y_j \vert z, x) \propto \text{exp} (w_j^T \text{BERT} _ \text{MASK} (j) (\text{join} _ {\text{BERT}} (x, z_{\text{body}}))\]그리고 미세 조정 과정에서는 질문에 대한 답변 $y$를 생성한다. $S(z, y)$는 문서 $z$ 안에서 출력 $y$와 일치하는 모든 span의 집합이다. 예를 들어 $y$가 ‘Paris’라면 $S(z, y)$는 문서 $z$ 내 존재하는 ‘Paris’가 포함된 문장들이 될 것이다. 문서 $z$에 ‘The capital of France is Paris.’, ‘Paris is known for the Eiffel Tower.’, ‘The Louvre in Paris is a major tourist attraction.’ 이렇게 세 문장이 ‘Paris’를 포함하는 문장이라면 $S(z, y)$는 이 세 문장이 될 것이다. 모델은 각 span에 대해서 $y$를 생성할 확률을 계산하고 이를 모두 합하여 최종적인 $y$의 확률을 계산한다.
\[p( y \vert z, x) \propto \sum_{s \in S(z, y)} \text{exp} (\text{MLP} ([h _ {\text{START} (s)} ; h _ {\text{END} (s)}]))\]
Injecting Inductive Biases into Pre-Training
REALM의 사전 학습 단계에서는 보다 효과적인 학습을 위해 [MASK] 토큰을 예측할 때 world knowledge를 필요로 하는 예시들을 선별적으로 사용한다. BERT 모델의 maksed language modeling 작업에서는 [MASK] 토큰을 무작위로 배치한다. 하지만 REALM에서는 “United Kingdom”이나 “July 1969”와 같이 world knowledge을 요구하는 부분에 [MASK] 토큰을 배치한다. 이는 ‘of’나 ‘and’와 같이 중요하지 않은 단어들이 [MASK] 토큰의 정답이 되는 것을 방지하는 것이다. 이 과정을 위해서 BERT-based tagger를 통해 entities를 구별하거나 정규 표현식을 통해 날짜 정보를 구분하여 [MASK] 토큰을 할당한다.
그러나 모든 [MASK] 토큰이 world knowledge를 필요로 하는 것은 아니다. 이 경우에는 상위 k개의 문서를 검색할 때 ‘null document’라는 표시인 $\emptyset$를 포함시킨다. 즉 retrieval이 필요하지 않다는 표시인 것이다.
그리고 사전 학습 단계에서 사용하는 말뭉치 $\mathcal{X}$와 실제 task에서 사용하는 말뭉치 $\mathcal{Z}$가 동일할 수 있다. 이 상황에서는 masking이 된 문장이 검색된 문서 $z$와 같기 때문에 인코더는 [MASK] 토큰을 예측하기 위해서 문서 $z$에서 직접 정보를 그대로 가져오기만 하면 된다. 하지만 이는 문서가 masking된 문장에 너무 많은 정보를 제공하는 경우에 해당한다. 이렇게 되면 모델은 특정 문서를 선택할 때 매우 확신하게 되고, 학습 과정에서 특정 문서에 대한 모델의 선호도가 지나치게 커진다. 모델이 특정 문서에만 과도하게 의존하게 하고, 모델의 일반화 능력을 저하시킨다. 그래서 사전 학습 단계에서는 해당 경우를 모두 제외한다.
학습 초기 단계에 retriever는 아직 충분히 좋은 임베딩을 학습한 상태가 아니다. 그래서 검색한 문서 $z$가 문장 $x$와 아예 관련이 없을 가능성이 높다. 이런 상황에서는 인코더가 유용한 문서를 찾는 능력을 제대로 학습하지 못하면서 계속해서 무관한 문서를 찾아낸다. 이러한 cold-start 문제를 해결하기 위해서 Inverse Cloze Task(ICT)라는 특별한 훈련 방식을 도입한다. 이 방식은 주어진 문장이 원래 포함되어 있던 문서에서부터 찾도록 모델을 훈련시키는 방법이다. 이는 모델이 문장과 문서 간의 관련성을 인식하고 이해하는 능력을 발달시키는 데 도움을 준다.
paper