Self-Rewarding Language Models
현재 인간의 선호도를 모델에 반영하기 위해서는 인간의 직접적인 개입이 필요하다. 이 과정에서 사용되는 것이 Reinforcement Learning from Human Feedback(RLHF) 방법이다. 이 방식에서는 인간의 선호도 데이터를 기반으로 하여 reward 모델을 훈련시키고, 이 reward 모델을 다시 LLM의 훈련에 사용해서 인간의 선호도를 모델에 반영한다.
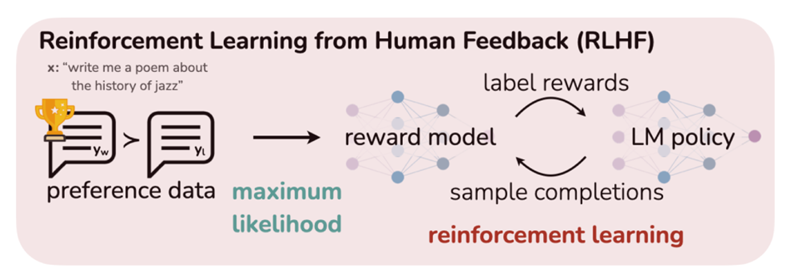
하지만 이 방식은 두 가지 단점이 있다. 먼저 인간의 성능 수준에 의해 제한될 수 있다. 그리고 인간의 선호도 데이터로 훈련된 reward 모델은 한번 훈련되면 고정되어 LLM이 훈련하는 도중 변하지 않는다. 보통 reward 모델은 훈련이 완료되면 추가적인 학습이나 조정이 이루어지지 않고 고정 상태로 남는다. 따라서 언어 모델은 계속해서 발전하더라도 reward 모델은 그 발전을 따라가지 못하고 초기에 훈련된 상태 그대로 남게 된다. 즉 reward 모델은 언어 모델 훈련 중 스스로 개선하거나 학습할 수 없다. 이러한 문제에 대응하여 본 논문에서는 언어 모델이 훈련 도중에 자체적으로 Self-Rewarding을 제공하는 새로운 접근 방식을 제안한다. 이 방식에서는 reward 모델과 언어 모델이 각각 따로 존재하지 않게 되어서 위의 두 가지 단점을 해결할 수 있다. 언어 모델이 자체적으로 응답의 질을 평가하는 LLM-as-a-Judge 방식이 활용되기 때문이다. 이 접근 방식은 언어 모델이 지시사항을 따르는 능력 뿐만 아니라 스스로 고품질의 reward를 제공하는 능력을 향상시키는 것을 가능하게 한다. 이로 인해 언어 모델은 인간의 선호도를 더 정확하게 반영하며 동시에 자체적인 훈련 과정을 통해 지속적으로 개선될 수 있는 잠재력을 가진다.
Self-Rewarding 모델은 두 단계로 이루어진다.
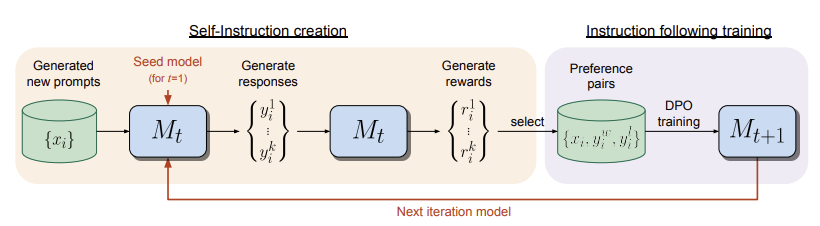
- Self-Instruction Creation: 새롭게 만들어진 prompt는 $M_t$ 모델로부터 응답 후보들을 생성할 때 사용된다. 이 후보들이 생성되면 LLM-as-a-Judge 방식을 통해 이들을 평가한다. 여기서 LLM-as-a-Judge 방식은 GPT-4와 같은 LLM이 응답을 평가를 하는 접근 방식을 말한다.
- Instruction Following Training: 가장 높은 점수를 받은 응답과 가장 낮은 점수를 받은 응답을 합쳐서 preference 쌍을 만든다. 이 쌍은 DPO 방식을 통해 훈련에 활용된다. 이렇게 훈련된 모델은 $M_{t+1}$이 된다.
Self-Rewarding 모델은 기본적으로 사전 훈련된 언어 모델과 인간이 주석을 단 소량의 데이터에 대한 접근을 가정한다. 그 후에 지시사항을 따르는 능력과 스스로 수정된 지시사항을 생성하는 능력을 갖춘 모델을 구출한다. 지시사항을 따르는 능력이란 prompt가 주어졌을 때 고품질의 유용한 응답을 생성해내는 능력을 말한다. 그리고 스스로 지시사항을 수정하는 능력이란 훈련 데이터에 새롭게 추가할 prompt를 생성하고 평가하는 능력이다. 이 능력을 갖추게 되면 reward 모델이 필요가 없게 된다.
Initialization
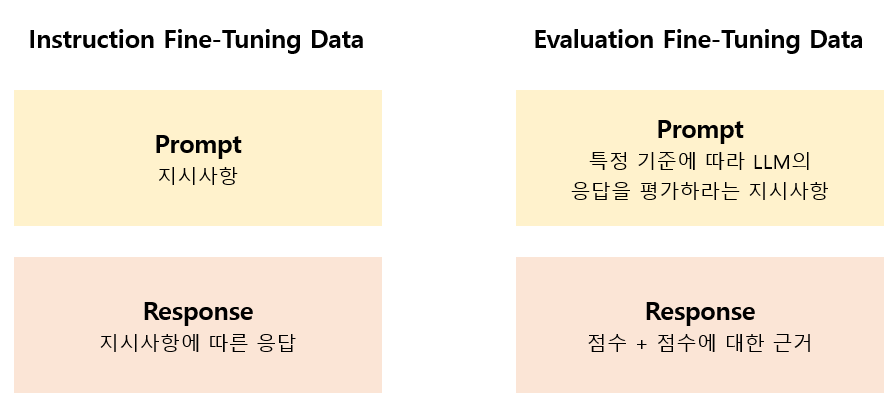
먼저 사람이 생성한 데이터를 학습하는 과정이다. 학습 데이터는 지시사항(instruction)과 그에 대한 응답으로 이루어져 있으며, Open Assistant 데이터셋에서 3200개를 선발했다. 이 데이터들은 Open Assistant에서 응답 품질이 높다고 평가된 상위 순위의 예시들이다. Open Assistant Dataset은 multi-turn 대화 형식으로 구성되어 있기 때문에 각 대화의 첫 번째 turn만을 가져왔다. 이를 통해 모델은 supervised fine-tuning 방법으로 훈련된다. 이 데이터를 Instruction Fine-Tuning (IFT) 데이터라고 한다.
추가로 응답을 평가하는 내용의 데이터도 학습 데이터로 사용한다. 이 데이터는 응답에 대해 평가하라는 내용의 지시사항과 평가 응답으로 이루어져 있다. 위의 Instruction Fine-Tuning 데이터만을 사용해도 되지만 이 데이터를 함께 사용했을 때 모델의 성능이 향상되었다. 지시사항에는 응답을 평가할 때 고려해야 하는 기준들을 포함하고 있어, 모델이 특정 기준에 따라 응답의 질을 평가하게 한다. 그리고 평가 응답은 최종 점수와 함께 그 근거가 되는 chain-of-thought reasoning을 포함한다. 이 데이터는 reward model의 기능을 수행하며, Evaluation Fine-Tuning (EFT) 데이터라고 불린다. 이 데이터 또한 Open Assistant 데이터셋에서 만들어진다. Open Assistant 데이터셋에는 사람이 매긴 순위 정보가 포함되어 있다. 이 정보를 바탕으로 EFT 데이터를 구성할 수 있다. 그러나 Open Assistant 데이터셋에는 응답에 대한 0점부터 5점까지의 점수와 그 근거가 되는 chain-of-thought reasoning이 포함되어 있지 않다. 따라서 IFT 데이터로만 미세 조정된 모델을 사용하여 chain-of-thought reasoning과 점수 부여 작업을 수행해야 한다. 이 과정에서는 Open Assistant 데이터셋 내에서 인간에 의해 매겨진 순위와 LLM이 매긴 점수 순위가 비슷한 데이터만을 선별한다.
Self-Instruction Creation
훈련된 모델은 자체적으로 훈련 데이터를 수정한다. 이 과정에서 추가적으로 생성된 훈련 데이터는 훈련의 다음 단계에서 사용된다. 먼저 (1) $x_i$라는 새로운 지시사항을 생성한다. 이때 few-shot prompting 방식을 사용하여 IFT 데이터에서 몇 개의 예시를 선택하여 추가한다. 이렇게 생성된 새로운 prompt에 대해 (2) $N$개의 응답 후보를 생성한다. 그리고 LLM-as-a-Judge 방식을 통해 (3) LLM이 $N$개의 응답 후보 각각에 대해 0점부터 5점까지 점수를 매긴다.
Instruction Following Training
초기 훈련은 IFT 데이터와 EFT 데이터를 사용하여 진행된다. 이후 AI Feedback 과정을 통해 훈련 데이터에 추가 데이터를 생성하여 보강한다 보강한다. 이 과정에서 생성된 데이터를 AI Feedback 훈련 데이터(AIFT)라고 한다. 이 데이터는 모델이 스스로 지시사항을 수정하고 추가적인 훈련 데이터로 활용함으로써 얻어진다. AIFT 데이터는 두 가지 형태로 나뉜다.
- Preference Pair: 특정 지시사항 $x_i$에 대해 생성된 응답 중 가장 높은 점수를 받은 응답을 $y_i^w$로 하고, 가장 낮은 점수를 받은 응답을 $y_i^l$로 하여 쌍을 형성한다. 이 쌍들은 DPO를 통해 preference tuning에 사용된다.
- Positive Examples Only: 높은 점수를 받은 5개의 응답만을 선정하여 fine-tuning 과정에 예시로 추가한다.
실험 결과에 따르면 Positive Examples Only 방식이 더 우수한 성능을 보였다.
Overall Self-Alignment Alogrithm
-
$M_0$: 사전 학습된 base 모델로 아직 fine-tuning이 되지 않은 상태의 모델이다.
-
$M_1$: $M_0$ 모델에서 IFT 데이터와 EFT 데이터로 fine-tuning을 진행한다.
-
$M_2$: $M_1$ 모델에서 시작하여 $M_1$ 모델이 생성한 AI Feedback 학습 데이터로 훈련한다. 이때 훈련 방법으로 DPO를 사용한다.
-
$M_3$: $M_1$ 모델에서 시작하여 $M_2$ 모델이 생성한 AI Feedback 학습 데이터로 훈련한다. 이때 훈련 방법으로 DPO를 사용한다.
즉 $t$번째 모델은 $t-1$번째 모델로 수정한 학습 데이터를 사용하는 것이다. 이 과정이 반복되면 reward 모델은 고정 상태로 남지 않으며 스스로 발전할 수 있다.
paper