Improving Factuality and Reasoning in Language Models through Multiagent Debate
Introduction
대규모 언어 모델(LLM)은 때때로 hallucination을 일으키거나 추론 과정에서 비합리적인 도약을 하곤 한다. 여기서 hallucination이란 모델이 실제 사실에 기반하지 않고 잘못된 정보나 존재하지 않는 사실을 생성해내는 현상을 말한다. 이 문제를 해결하기 위해 모델의 답변이 사실인지 판단하는 사실적 정확성와 추론 과정을 향상시키는 다양한 방법론이 제안되었다. 예를 들어 few-shot이나 zero-shot CoT를 사용하는 것, 답변 후 검증 단계를 거치는 것, self-consistency를 사용하는 것 등이 있다. 하지만 이러한 방법들은 단일 모델 인스턴스만을 사용한다. 본 논문에서는 여러 개의 모델 인스턴스를 사용하는 다중 에이전트(multi-agent) 설정에서의 방법론을 제안한다. 이 방법론에서는 여러 언어 모델이 각자 답변을 하고, 서로의 답변과 사고 과정에 대해 토론한 후 하나의 최종 결론을 도출한다. 즉 질문이 주어지면 각 모델 인스턴스는 초기 답변을 생성해낸다. 이후 모델들은 서로의 답변을 읽고 다른 모델의 답변에 대해 비판하며 이를 자신의 원래 답변을 업데이트하는 데 사용한다. 이 과정은 여러 라운드에 걸쳐 반복된다.
이 토론 방식은 6개의 벤치마크에서 zero-shot CoT나 reflection과 같이 단일 모델만을 사용한 기존 방식보다 높은 성능을 보여주었다. 그리고 여러 모델 에이전트를 사용한 것과 여러 라운드에 걸쳐 토론을 진행한 것이 성능 향상의 주요 원인이라고 설명한다. 또한 이 방법은 거짓 정보를 덜 포함한다. 토론이 계속됨에 따라 각 모델 인스턴스는 불확실한 사실에 대해 동의하지 않으면서 그 사실들을 답변에서 제외하는 경향을 보였기 때문이다. 실제로 처음에는 잘못된 답변을 제시했지만 토론을 거쳐 올바른 답변을 도출하는 경우가 확인되었다. 이 방법은 모든 task에 대해 적용이 가능하며 질문에 대한 답변을 생성할 수 있는 언어 모델에 대한 단순한 접근만을 요구한다. 또한 이 방법은 다른 모델 생성 개선 방법과 결합하여 사용될 수 있다. 하지만 이 방법의 단점은 비용이 많이 든다는 것이다. 또한 본 논문에서는 유명한 과학자들의 전기에 대해 사실 확인을 하는 새로운 벤치마크도 제시한다. 현재 존재하는 언어 모델들은 잘못된 정보를 만들어내는 경향이 있어 관련 기관과 날짜를 잘못 표현하기도 한다. 그러나 토론을 하면 이런 일관성 없는 사실들은 제거되고 수정된다.
Language Generation through Multiagent Debate
Multiagent Language Generation
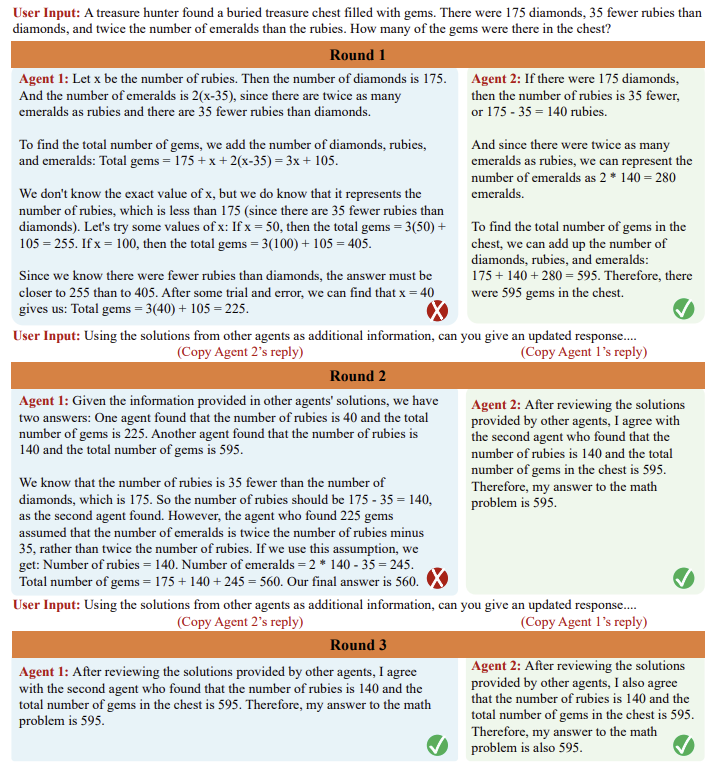
변의 길이가 3, 4, 5인 삼각형의 넓이를 구하는 수학 문제를 예로 들어본다. 먼저 변의 길이가 3, 4, 5인 경우 직각삼각형임을 알 수 있으며, 넓이는 $3 \times 4 \times 0.5$로 계산할 수 있다. 만약 여러 모델 인스턴스가 동일한 답을 제시하면 해당 답변에 대한 신뢰도가 증가한다. 그러나 답변이 서로 다를 경우에는 모델들은 토론을 시작하여 각자의 추론 과정을 검토한다. 이 과정은 하나의 일관된 답변이 나올 때까지 반복된다.
각 에이전트가 초기 답변을 제시한 후 토론의 첫 번째 라운드가 시작된다. 이때 다른 에이전트들의 초기 답변들은 맥락으로 제공되며, 각 에이전트는 이를 바탕으로 새로운 답변을 도출한다. 에이전트들은 서로의 답변을 검토하고 자신의 답변을 수정하는 과정을 거친다. 이러한 절차는 여러 번 반복되면서 더 정확하고 일관된 답변을 도출해낼 수 있다.
Consensus in Debates
사실 모델 인스턴스들이 하나의 최종 답변으로 합의에 이를지 여부는 확실하게 보장되지 않는다. 그러나 여러 차례의 토론을 거치면서 하나의 최종 답변으로 수렴하는 경향이 있음을 경험적으로 확인할 수 있었다.
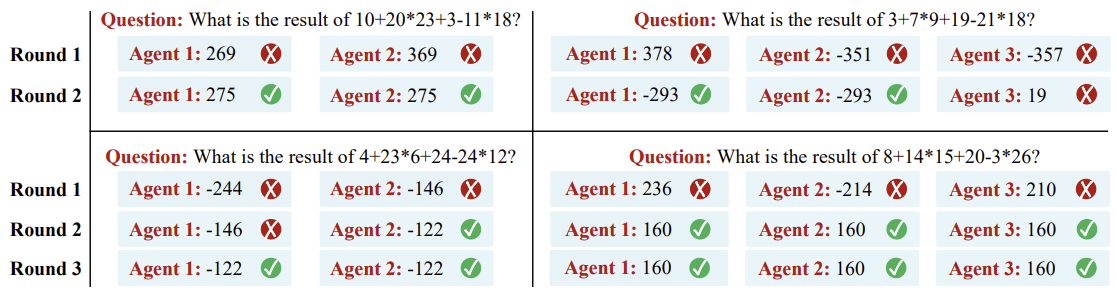
모든 에이전트들이 처음에는 틀린 답변을 제시했음에도 여러 라운드의 토론을 거친 후에는 정답을 도출해내기도 했다.

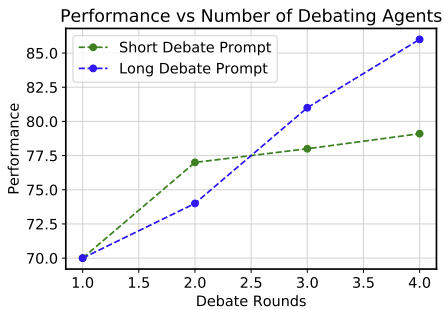
각 에이전트가 다른 에이전트의 답변을 검토하고 자신의 답변을 수정하도록 유도하는 prompt는 두 가지 유형이 있다. 첫 번째 유형의 prompt는 토론을 짧게 마무리하도록 유도하는 반면 두 번째 유형의 prompt는 토론을 더 길게 이어가는 경향이 있었다. 일반적으로 두 번째 유형의 prompt를 사용했을 때 모델은 자신의 답변을 고수하는 경향이 더 강해져 토론이 장기화되며, 이 과정에서 더 정교한 답변을 도출하는 경향이 있음을 관찰했다. 그리고 언어 모델 에이전트들은 비교적 협조적인 성향을 보였는데, 이는 instruction tuning이나 사람에 의한 피드백을 기반으로 강화학습을 하였기 때문인 것으로 추정된다.
Experiments
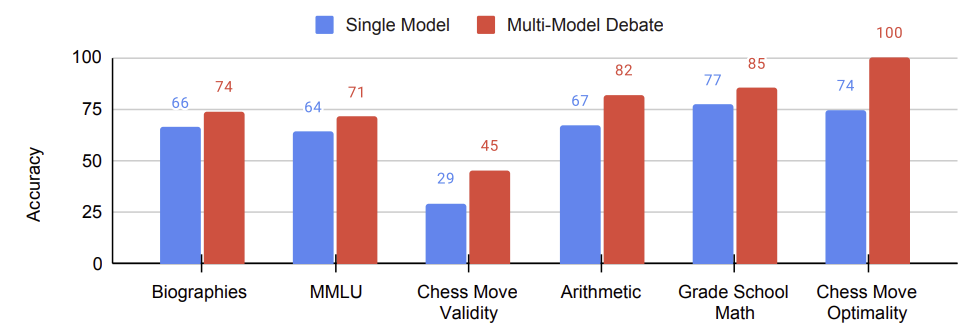
Baseline으로 세 가지 접근 방식을 사용하였다. 첫 번째는 하나의 모델만을 사용해 바로 답변을 제시하는 것이다. 두 번째는 하나의 모델로 답변을 내놓은 후 자체적인 피드백을 반영하여 답변을 수정하는 것이다. 마지막으로 여러 모델을 사옹하여 답변을 낸 후 가장 자주 나온 답변을 최종 답변을 선택하는 것이다. 결과적으로 단일 모델을 사용하는 것보다는 여러 모델을 사용하는 경우 성능이 향상되었다. 특히 여러 모델로 토론을 진행했을 때 성능이 가장 높았다.

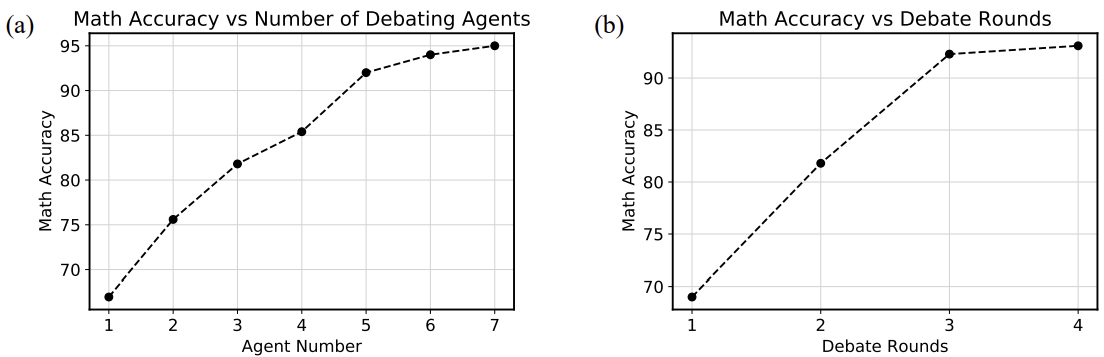
에이전트 수를 증가시킬 때 성능이 향상되는 것을 확인했다. 그러나 에이전트 수를 늘림으로써 발생할 수 있는 context length error를 방지하기 위해 에이전트 수가 많을 경우 chatGPT를 사용하여 모든 에이전트의 답변을 요약하도록 했다. 아래 그래프에서 에어전트 수가 다섯 이상일 때 요약을 진행하였다. 에이전트 수가 많지 않을 때에도 chatGPT를 이용하여 요약 후 토론을 진행하면 성능이 소폭 개선되었다. 그리고 토론의 라운드 수를 증가시킬 때 성능이 개선되는 것을 확인했으나 네 번째 라운드 이후부터는 성능이 비슷한 수준을 유지했다.
paper