Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
Abstract
사전 훈련된 대규모 언어 모델은 매개변수에 지식을 저장하고, downstream NLP task에 미세 조정될 때 State-of-the-Art(SOTA)를 달성한다. 하지만 이러한 모델들이 지식을 활용하는 능력은 여전히 제한적이다. 특히 많은 양의 외부 지식을 필요로 하는 지식 집약적인 task에서는 그 task에 특화된 아키텍처보다 성능이 떨어진다. 또한 모델이 내린 결정에 대한 근거를 제공하고 지식을 업데이트하는 방법은 아직 충분히 연구되지 않았다. 그리고 non-parametric memory을 사용하는 메커니즘을 갖춘 사전 훈련된 모델은 주로 텍스트에서 특정 정보를 추출하는 task에 초점을 맞춰 연구되었다. 생성 작업에서 이러한 접근 방식을 어떻게 적용할 수 있는지에 대한 탐구는 아직 초기 단계이다. 본 논문에서는 텍스트를 생성할 때 parametric memory와 non-parametric memory를 모두 사용하는 RAG 모델을 제안한다.
- Parametric Memory: 사전 훈련된 seq2seq 모델이다. 입력 시퀀스를 받아 출력 시퀀스를 생성하는 구조로, 학습 과정에서 얻은 지식이 모델의 매개변수에 저장되어 있다.
- Non-parametric Memory: Wikipedia 데이터의 밀집 벡터 인덱스로 구성되었다. 사전 훈련된 신경망 검색기를 통해 이 데이터에 접근할 수 있다. 이 신경망 검색기는 모델이 필요할 때 실시간으로 관련 정보를 검색할 수 있게 한다.
이렇게 parametric memory는 내재된 학습 지식을 제공하고, non-parametric memory는 실시간으로 검색 가능한 정보를 추가적으로 제공한다. 본 논문에서는 전체 시퀀스를 생성해낼 때 모든 토큰에 대해 동일한 문서를 사용하는 구성과 토큰마다 다른 문서를 사용하는 구성을 제안한다.
Methods
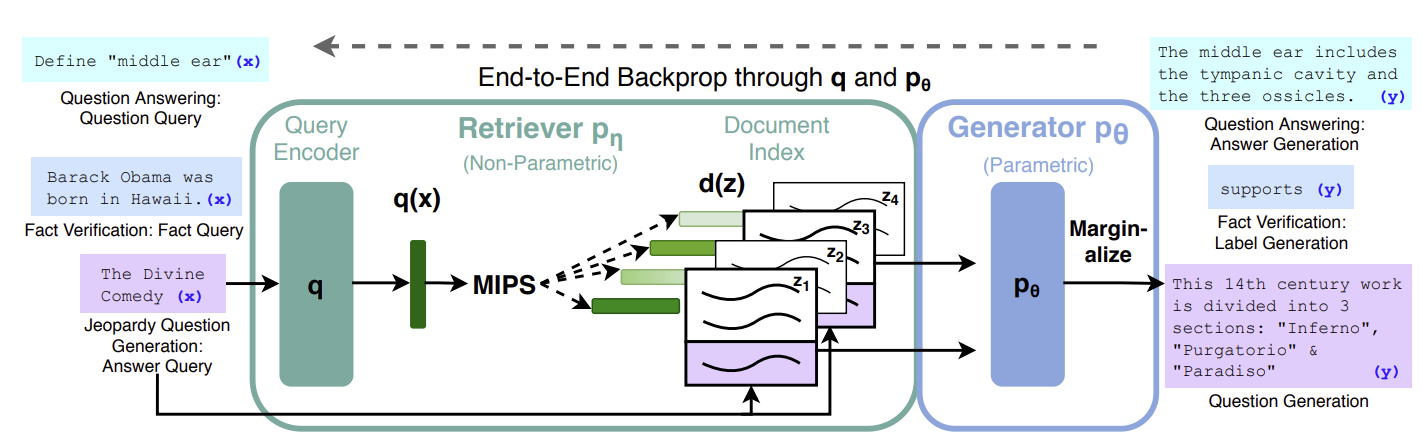
입력 시퀀스 $x$를 사용해서 문서 $z$를 retrieve한다. 그리고 이를 추가적인 context로 활용하여 타겟 시퀀스 $y$를 생성한다.
- Retriever: 입력 시퀀스 $x$를 기반으로 상위 $k$개의 문서를 retrieve한다. 이 과정은 입력 $x$에 대한 문서 $z$의 확률 분포 $p_\eta (z \vert x)$를 추정하는 것을 의미한다. 이 분포는 입력 시퀀스와 관련된 문서들을 얼마나 잘 검색할 수 있는지를 나타내며, 이를 통해 가장 관련성이 높은 문서들이 선택된다.
- Generator: 입력 시퀀스 $x$, retrieve한 문서 $z$, 그리고 이전에 생성한 $i-1$개의 토큰을 바탕으로 다음 토큰을 생성한다. 즉 $p_\theta (y_i \vert x, z, y_{1:i-1})$을 계산한다. 이 과정은 retrieve한 문서 $z$를 추가 context로 활용하여 주어진 입력에 대한 타겟 시퀀스 $y$의 각 토큰을 순차적으로 생성하는 모델의 능력을 나타낸다.
이러한 retriever와 generator를 end-to-end로 학습하기 위해서 retrieve된 문서 $z$를 잠재 변수로 취급하고 이를 marginalize하는 방법을 적용한다. 여기에 두 가지 접근 방식이 있다. RAG-sequence에서는 시퀀스를 생성할 때 동일한 문서를 사용한다. 한 번 검색된 문서를 전체 생성 과정에 걸쳐 고정된 컨텍스트로 사용하는 것을 의미한다. 반면 RAG-token에서는 생성하는 각 토큰마다 다른 문서를 사용한다. 토큰 별로 가장 관련성 높은 정보를 검색하여 사용하는 것이다.
Introduction
현재 사전 훈련된 언어 모델은 몇 가지 주요한 단점이 있다. 모델의 지식을 업데이트하고 수정할 수 없으며 그들이 낸 예측에 대한 통찰을 직접적으로 제공하기 어렵다. 그리고 때로는 근거 없는 내용(hallucination)을 생성하기도 한다. 이러한 문제를 해결하기 위해 parametric memory와 non-parametric memory를 결합하는 방식이 제안되었다. 이 결합을 통해 지식은 수정되고 확장될 수 있으며 모델의 해석력이 향상된다. 실제로 REALM과 같은 연구에서 이러한 접근 방식이 유망한 결과를 보여주었다. 하지만 주로 open-domain extractive question answering task에만 한정되었다.
본 논문에서는 parametric memory와 non-parametric memory의 결합을 널리 사용되는 seq2seq 모델에 적용하여 이러한 접근 방식의 범위를 확장하였다. RAG 모델에서 parametric memory는 사전 훈련된 seq2seq 트랜스포머 모델로 복잡한 언어 구조를 학습하는 데 사용된다. 그리고 non-parametric memory는 사전 훈련된 신경망 검색기를 통해 접근 가능한 Wikipedia의 밀집 벡터 인덱스로 실시간으로 관련 정보를 검색하는 데 활용된다. 이 두 종류의 memory를 결합함으로써 모델은 입력에 대해 더 정확하고 관련성 높은 출력을 생성한다. 모델의 학습 과정에서 retriever는 잠재 변수로 사용될 문서를 제공한다. 이 문서는 입력과 함께 조건으로 사용되어 출력을 생성한다. RAG 모델은 다양한 seq2seq task에 미세 조정될 수 있으며 parametric memory와 non-parametric memory가 같이 사전 훈련되었기 때문에 추가적인 학습 없이도 모델이 지식에 접근할 수 있다. 이 모델은 사람이 직접 외부 검색 없이는 수행할 수 없는 task에 대해서 우수한 성능을 보여주었다.
Models
-
RAG-sequence: 전체 시퀀스에 걸쳐 동일한 문서를 사용한다. 따라서 retriever가 $k$개의 문서를 retrieve하면 generator는 각 문서를 기반으로 출력 시퀀스를 생성한다. 이후 생성된 각각의 시퀀스에 대해 marginalize하여 최종 출력을 결정한다.
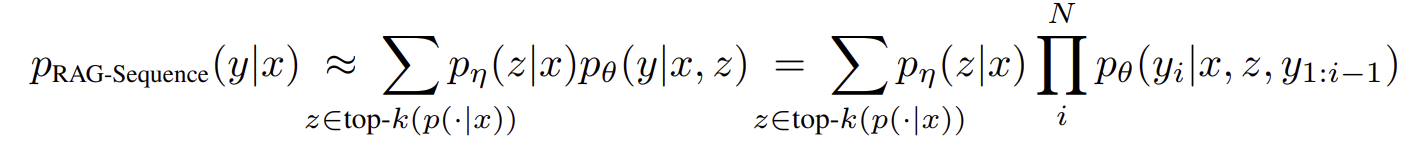
-
RAG-token: 각 토큰마다 다른 문서를 사용한다. 따라서 retriever가 $k$개의 문서를 retrieve하면 이 문서들에 대해 marginalize를 하는 과정을 각 토큰 생성 단계마다 진행한다.
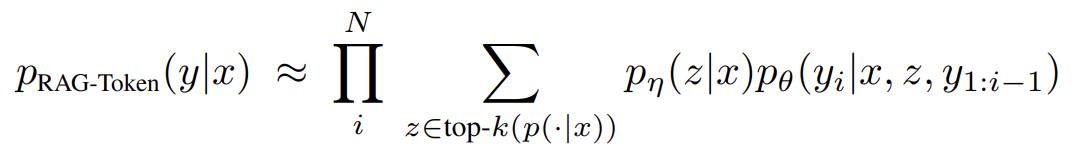
Retriever: DPR
Retriver의 $p_\eta (z \vert x)$는 bi-encoder 구조를 따르는 DPR(Dense Passage Retrieval)에 기반을 두고 있다.
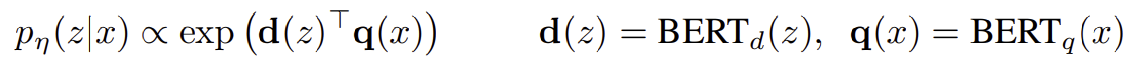
여기서 $d(z)$는 $\text{BERT} _ {\text{BASE}}$의 인코더에 의해 생성된 문서의 밀집 표현이다. 그리고 $q(x)$도 $\text{BERT} _ {\text{BASE}}$의 인코더에 의해 생성된 쿼리의 표현이다. 상위 $k$개의 문서를 retrieve하기 위해 가장 높은 확률 $p_\eta (z \vert x)$을 가지는 문서 목록을 계산할 때 Maximum Inner Product Search(MIPS)을 사용한다. Maximum Inner Product Search(MIPS)는 쿼리 벡터와 데이터베이스 내 모든 벡터 간의 내적을 계산하고 그 결과가 가장 높은 벡터를 선택한다.
Generator: BART
어떤 인코더-디코더 모델을 사용하여도 $p_\theta (y_i \vert x, z, y_{1:i-1})$을 모델링할 수 있다. 본 논문에서는 4억 개의 매개변수를 갖는 사전 훈련된 seq2seq 트랜스포머 모델인 $\text{BART-large}$을 사용하였다. 입력 $x$와 문서 retrieve된 context $z$를 결합할 때에는 단순히 둘을 연결했다.
Training
미세 조정 과정에서는 retriever와 generator는 어떤 문서가 검색되어야 하는지에 대한 직접적인 지시 없이 함께 훈련된다. 입력과 출력 쌍 $(x_j ,y_j)$으로 구성된 훈련 corpus를 사용하여 $\sum_j -\text{log} \ p(y_j \vert x_j)$를 최소화한다. 이 과정은 Adam 최적화 알고리즘을 사용한 확률적 경사 하강법으로 수행된다. 훈련 중 문서 인코더를 업데이트하기 위해서는 주기적으로 문서 인덱스를 업데이트해야 하기 때문에 비용이 많이 든다. 본 논문에서는 이 단계가 강력한 성능을 위해 필수적이라고 생각하지 않아서 문서 인코더를 고정하고 쿼리 인코더와 generator만 미세 조정하였다.
Generator
RAG-sequence와 RAG-token은 다른 방식의 디코딩 방법을 사용한다.
- RAG-token: 이 모델은 표준적인 autoregressive seq2seq generator라고 볼 수 있다. 따라서 디코딩을 위해 $p_\theta (y_i \vert x, z, y_{1:i-1})$을 standard beam decoder에 적용할 수 있다. 여기서 beam search는 시퀀스 생성 작업에서 최적의 결과를 찾기 위해 사용되는 search 알고리즘이다. 단순히 가장 높은 확률을 가진 단일 경로를 탐색하는 것이 아니라 한 번에 여러 개의 최상의 후보 시퀀스를 추적해서 더 넓은 범위의 최적의 시퀀스를 찾으려고 시도한다. Beam의 크기가 클수록 더 많은 후보를 탐색한다.
- RAG-sequence: 이 모델은 $p(y \vert x)$의 likelihood가 토큰 별 likelihood로 나뉘지 않기 때문에 standard beam decoder을 적용할 수 없다. 대신 각 문서 $z$에 대해서 beam search를 수행하고, 각 가설을 $p_\theta (y_i \vert x, z, y_{1:i-1})$을 사용하여 점수를 매긴다. 가설이란 생성 과정에서 고려되는 잠재적인 시퀀스를 의미한다. 점수는 가설의 품질을 평가하는 데 사용된다. 이 과정을 통해 가설의 집합 $Y$가 생성된다. 이때 일부 가설은 모든 문서의 beam에서는 나타나지 않을 수 있다. 문서 $z$ 각각에 대해서 beam search를 수행하기 때문에 전체 문서 집합을 고려했을 때 특정 가설은 어떤 문서의 beam에서는 나타나지만 다른 문서의 beam에서는 나타나지 않는다. 이는 각 문서 $z$가 서로 다른 정보를 담고 있기 때문이다. 따라서 최종적으로 어떤 가설들은 모든 문서에 대한 beam에 포함되지 않을 수 있다. 이는 모든 문서를 고려했을 때 해당 가설이 좋지 못하다는 것을 의미할 수도 있지만 실제로는 좋은 후보일 수 있으므로 추가적인 평가를 수행한다. 가설 $y$의 확률을 추정하기 위해 beam에 나타나지 않는 각 문서 $z$에 대해서 추가적인 forward pass를 실행하고 $p_\eta (z \vert x)$를 곱한 후 확률을 합산한다. 이 절차를 “Thorough Decoding”이라고 한다. 이렇게 함으로써 모델은 검색된 모든 문서의 정보를 최대한 활용하여 보다 정확하고 관련성 높은 출력을 생성할 수 있다. 그런데 출력 시퀀스가 길어질수록 $Y$의 크기가 커져서 많은 forward pass가 필요할 수 있다. 따라서 효율적인 디코딩을 위해서 beam search 중 생성되지 않은 $y$에 대해 $p_\theta (y \vert x, z_i) \approx 0$으로 근사할 수 있다. 이 절차를 “Fase Decoding”이라고 한다.
paper