Training Language Models to Follow Instructions with Human Feedback (InstructGPT)
Background and Motivation
Simply scaling up language models does not guarantee that they will operate according to user intentions. These models may produce hallucinations, generate biased or toxic text, or fail to follow human instructions. This issues stems from the traditional objectives of language models, which have primarily focused on predicting the next token. Such objectives do not align with the goals of safely and honestly following user directives. To address this misalignment, this paper introduces a method of fine-tuning language models using human feedback to ensure they align more closely with user intentions. The resulting models are called InstructGPT.
It is important for language models to be both helpful and honest while avoiding causing psychological or social harm due to their utility in broad applications. Using the language of Askell, language models should be built around three key principles: helpfulness, honesty and harmlessness. First, they need to be helpful as language models are designed to assist in solving problems. Language models must adhere closely to the instructions provided by users. Second, maintaining honesty is important as making up false information can destroy user trust. Lastly, they must be harmless, ensuring they do not create content that could cause psychological or social harm. Aligning language models to follow user instructions accurately and safely is crucial for their practical application in real-world scenarios.
Prior Research
Reinforcement learning from human feedback (RLHF) is a methodology aimed at supplementing language model performance by using written human feedback during training. This approach has been previously utilized in specialized tasks such as summarization and translation. However, this paper extends its application broadly across various language tasks.
Furthermore, there have been several efforts to reduce harm associated with language model outputs. These include applying specific criteria to remove documents and thereby filter datasets, blocking particular words, and using word embedding regularization to decrease bias. Unlike these methods, which often involve some loss of data or a decline in performance, the approach in this paper seeks to eliminate harm without significantly compromising performance. This was achieved by adding a term that prevents performance degradation to the objective function in RL training.
Methods
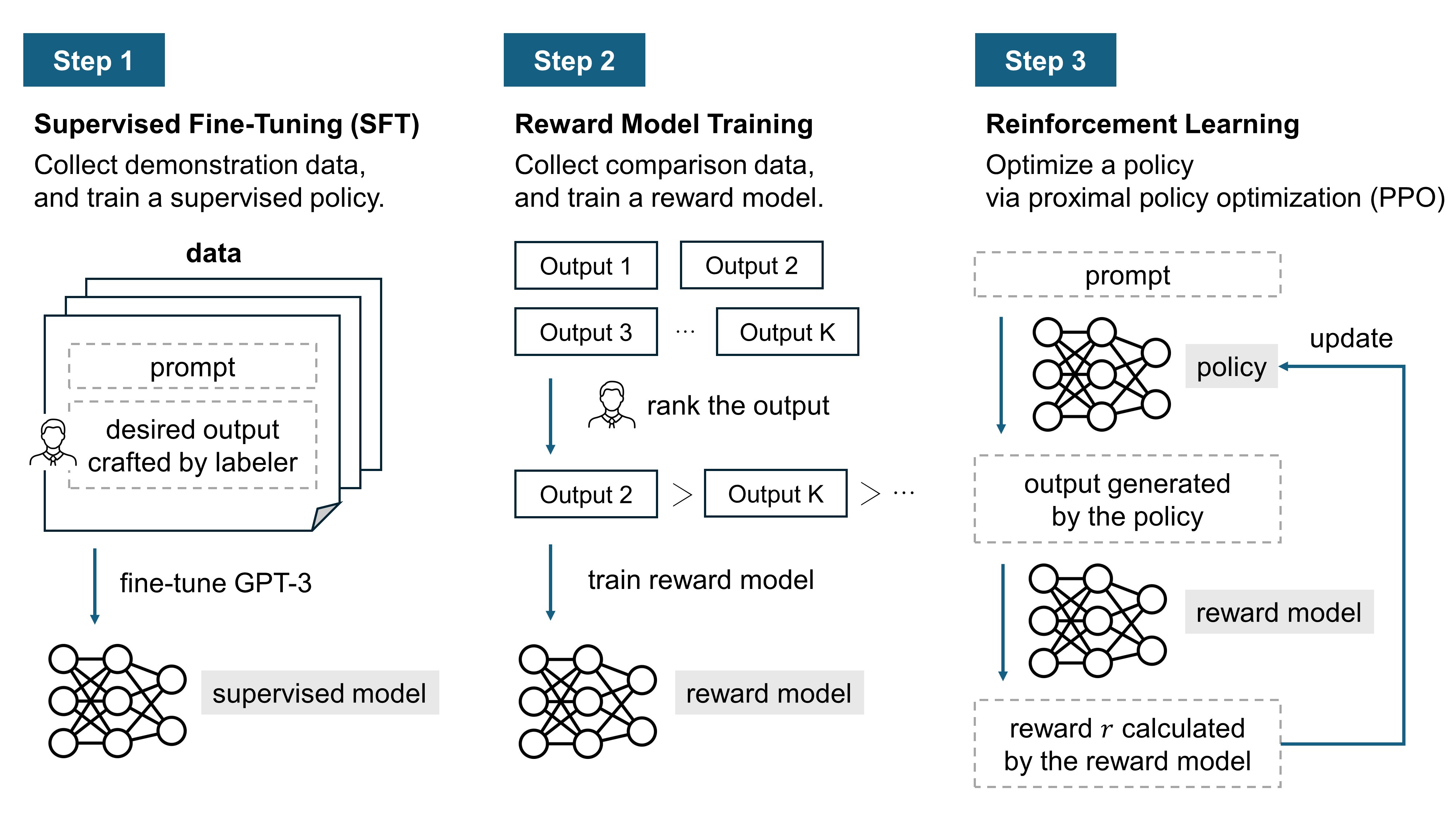
The following is how InstructGPT was developed, explained step by step. This shows how the model was built to better follow user instructions and work more effectively.
Step 1: Supervised Fine-Tuning (SFT)
The process starts with a pretrained language model. This model was initially trained on large amounts of data from the Internet, so performs well across various tasks but can be unpredictable in some situations. To make the model act more in line with human intentions, it undergoes fine-tuning. For this fine-tuning, a dataset is created using prompts and labels that consist of desirable responses crafted by humans. This data is then used to perform supervised learning to fine-tune GPT-3.
Step 2: Reward Model (RM) Training
In this phase, another dataset is created. Humans evaluate the responses generated by the model, ranking them based on their preferences. This data is then used to train a reward model. The reward model is designed to predict the human-preferred output. If it takes in a prompt and response, it outputs a scalar reward.
\[\text{loss}(\theta) = - \frac{1}{\binom{K}{2}} E_{(x, y_w, y_l) \sim D} \left[ \log \left( \sigma \left( r_{\theta} (x, y_w) - r_{\theta} (x, y_l) \right) \right) \right]\]where $r_{\theta}(x, y)$ is the scalar output of the reward model for prompt $x$ and completion $y$ with parameters $\theta$, $y_w$ is the preferred completion out of the pair of $y_w$ and $y_l$, $D$ is the dataset of human comparisons, and $K$ is the total number of completions or responses evaluated, with the binomial coefficient $\binom{K}{2}$ representing the number of unique pairs that can be formed from $K$ items.
This loss function aims to maximize the log odds of the difference between the rewards for preferable and less desirable responses.
Step 3: Reinforcement Learning via Proximal Policy Optimization (PPO)
In this step, the supervised model from Step 1 undergoes further fine-tuning through reinforcement learning. This process utilizes the scalar rewards generated by the reward model. The model is fine-tuned with the Proximal Policy Optimization (PPO) algorithm, which is designed to maximize these rewards. PPO algorithm includes a KL divergence term in the loss function to prevent the new policy from deviating too much from the previous one. Additionally, in this model, an extra KL divergence term is added so the pretraining gradients are mixed with the PPO gradients to prevent severe degradation of performance on the NLP dataset. This enhanced version of the model is referred to as PPO-ptx, which has been utilized in the development of InstructGPT.
\[\text{objective} (\phi) = \mathbb{E}_{(x,y) \sim D_{\pi_\phi^\text{RL}}} \left[ r_{\theta}(x, y) - \beta \log \left( \frac{\pi_{\phi}^{\text{RL}}(y \mid x)}{\pi^{\text{SFT}}(y \mid x)} \right) \right] + \gamma \mathbb{E}_{x \sim D_{\text{pretrain}}} \left[ \log(\pi_{\phi}^{\text{RL}}(x)) \right]\]where $\pi_{\phi}^{\text{RL}}$ is the learned RL policy, $\pi^{\text{SFT}}$ is the supervised trained model, and $D_{\text{pretrain}}$ is the pretraining distribution. The KL reward coefficient $\beta$, and the pretraining loss coefficient $\gamma$, control the strength of the KL penalty and pretraining gradients respectively.
The objective function in RL training includes two key terms: the second term uses a logarithmic function to ensure the optimized RL policy does not deviate too much from the supervised model. The third term ensures that the RL model performs well on the pretraining dataset, enhancing its general applicability.
Results and Limitations
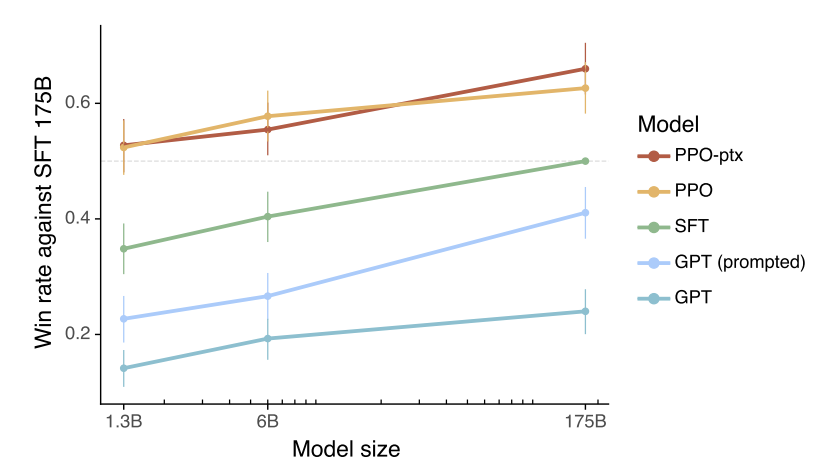
Labelers preferred the responses generated by InstructGPT over those from GPT-3, despite InstructGPT having significantly fewer parameters. InstructGPT produced answers that were deemed more favorable by humans and were found to be twice as truthful as those from GPT-3. These results are shown in the Figure. Additionally, InstructGPT generated fewer toxic responses compared to GPT-3. While the model exhibits a slight performance degradation on NLP datasets, it holds value due to its enhanced truthfulness and reduced toxicity in responses.
InstructGPT still exhibits several limitations. Despite improvements, it still produces toxic and biased responses. Additionally, the model requires a large amount of labeled data, which can be costly.
paper