Learning Transferable Visual Models From Natural Language Supervision
전통적으로 이미지는 미리 정해진 class 중 하나로 분류되어 왔기 때문에, 새로운 class를 학습하기 위해서는 추가적인 label이 달린 데이터가 필요했다. 이러한 방식은 새로운 개념을 학습할 때의 유연성이 부족하다. 이에 대한 해결책으로, 이 논문은 사전 훈련 단계에서 이미지와 해당 이미지에 대한 원시 텍스트를 함께 학습하는 방식을 제안한다. 이렇게 함으로써, 모델은 새로운 이미지가 주어졌을 때에도 해당 이미지를 설명하는 자연어를 생성할 수 있게 되며, 이를 통해 추가적인 학습 없이도 이미지를 분류할 수 있는 zero-shot 능력을 갖추게 된다. 결과적으로 단순한 분류 작업 뿐만 아니라 다양한 task를 아우르며 우수한 성과를 보였다. 즉 추가적인 미세 조정 없이 여러 task에 효과적으로 전이가 가능하다.
Natural Language Supervision
인간이 사용하는 자연어 텍스트를 학습에 활용하는 것이다. 이러한 접근 방식 자체는 새로운 것이 아니지만, 관련 연구들에서는 이를 unsupervised, self-supervised, weakly supervised, supervised 등 각자 다른 용어로 이를 설명하고 있다. 이 논문에서는 텍스트와 이미지가 결합된 데이터를 활용하여 시각적 표현을 학습하는 방법을 natural language supervision이라고 정의한다. Natural language supervision을 활용한 학습은 몇 가지 강점이 있다. 첫째, 별도의 정답 label이 필요하지 않기 때문에 scale하기가 쉽다. 인터넷에 존재하는 방대한 양의 텍스트를 label 없이 학습에 활용할 수 있기 때문이다. 둘째, 대부분의 unsupervised 또는 self-supervised 학습 방법과는 달리, 단순히 표현(representation) 자체를 학습하는 것이 아니라 그 표현을 언어와 연결하는 방법을 학습함으로써 유연한 zero-shot 전이를 가능하게 한다.
CLIP 모델의 훈련 알고리즘 pseudocode

Selecting an Efficient Pre-Training Method
이 논문에서는 Natural Language Supervision을 확장하는 데 있어 훈련 효율성이 매우 중요하다고 판단해서 최종적으로 이 기준에 따라 사전 훈련 방법을 선택했다. 초기에는 이미지 CNN과 텍스트 트랜스포머를 처음부터 같이 훈련하여 이미지 캡션을 예측하는 방법을 채택했다. 하지만 이 방법은 효율적으로 확장하기에 적합하지 않았다. 최근 contrastive representation learning 연구에 따르면 contrastive objective가 동일한 predictive objective보다 더 나은 표현을 학습할 수 있다고 한다. 다른 연구에서는 이미지 생성 모델이 높은 품질의 이미지 표현을 학습할 수는 있지만 동일한 성능을 가진 contrastive 모델에 비해 10배 이상의 계산량을 필요로 한다고 밝혔다. 이러한 연구 결과를 바탕으로 이 논문에서는 모델이 각 이미지에 대한 정확한 텍스트 단어를 예측하는 대신, 더 쉬운 방법으로 텍스트 전체가 어떤 이미지와 짝을 이루는지 예측하도록 했다. CLIP은 $N$개의 (이미지, 텍스트) 쌍으로 이루어진 batch를 사용하여 해당 batch 내의 $N \times N$개의 가능한 모든 (이미지, 텍스트) 쌍 중 실제 쌍은 무엇인지 예측하도록 훈련되었다. 이를 위해서 CLIP은 이미지 인코더와 텍스트 인코더를 공동으로 훈련하여 batch 내 $N$개의 실제 쌍의 이미지, 텍스트 임베딩 간 코사인 유사성을 최대화했다. 그리고 $N^2 - N$개의 잘못된 짝의 임베딩 간 코사인 유사성은 최소화했다. 즉 symmetric cross entropy loss를 사용하는 것이다.
사전 훈련 데이터셋이 매우 크기 때문에 여기서는 overfitting이 큰 문제가 되지 않는다. ImageNet의 가중치로 이미지 인코더를 초기화하거나 사전 훈련된 가중치로 텍스트 인코더를 초기화하지도 않았다. 또한 표현과 contrastive 임베딩 공간 간 비선형 projection을 사용하지 않았다. 여기서는 각 인코더의 표현을 multi-modal embedding space로 mapping하기 위해 선형 projection만 사용했다.
CLIP 모델의 전체적인 접근 방식
Summary of the CLIP model approach
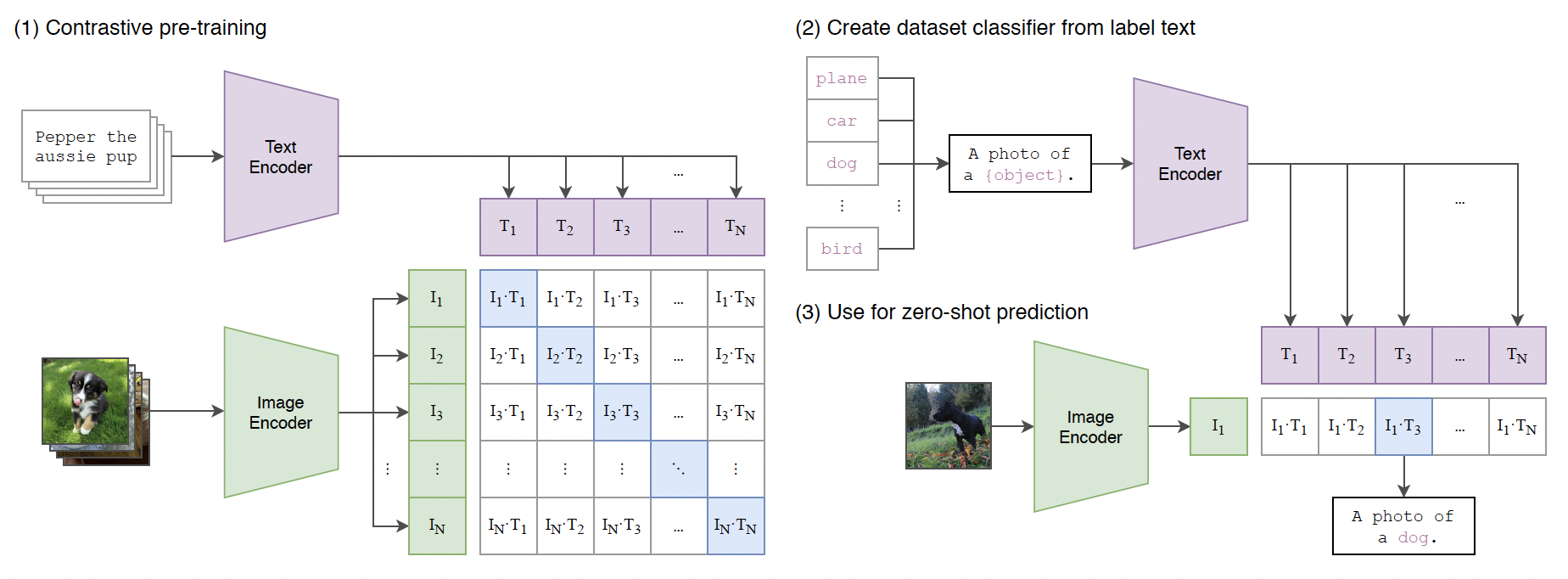
CLIP 모델은 이미지와 텍스트 쌍을 사용해서 모델을 훈련한다. 그리고 이를 통해 새로운 데이터에 대해 zero-shot 예측을 수행할 수 있도록 한다.
- Contrastive Pre-training: 이미지와 텍스트 쌍을 입력으로 받아 각각 이미지 인코더와 텍스트 인코더로 임베딩을 만든다. 각 이미지와 텍스트 임베딩 간의 코사인 유사성을 계산한다. 이때 정답 쌍의 코사인 유사성은 최대화하고, 잘못된 쌍의 유사성은 최소화하도록 학습한다.
- Create Dataset Classifier from Label Text: 각 label은 텍스트로 표현된다. 해당 class에 대한 설명이나 이름을 포함하는 문장을 텍스트 인코더에 입력한다.
- Use for Zero-Shot Prediction: 훈련된 이미지 인코더를 사용하여 새로운 이미지에 대해 임베딩을 생성한다. 이 이미지 임베딩과 label 텍스트 임베딩 간의 유사성을 계산한다. 예측하려는 이미지에 대해 가장 높은 유사성을 가진 텍스트 레이블이 예측 결과로 선택된다.
paper